[1. 서버 프로그램 구현]
Chapter01. 개발 환경 구축하기
section01. 개발 환경 도구
1. 개발 환경 구축
2. 개발 도구 선정 과정
3. 구현 도구의 선정
4. 빌드 도구와 형상관리 도구의 선정
* 기출 문제 - 2022년 1회 : 정적 분석, 동적 분석
06. 다음은 소스코드 품질 분석 도구에 대한 설명이다. 설명에 해당하는 분석 도구를 빈칸에 각각 <보기>에서 골라 쓰시오.
|
( ① ) Analysis
|
- 원시 코드를 분석하여 잠재적인 오류를 분석하며, 코딩 표준, 런타임 오류 등을 검증한다.
- 결함 예방/발견, 코딩 표준, 코드 복잡도 등을 분석하는 것이 가능하다. |
|
( ② ) Analysis
|
- 프로그램 수행 중 발생하는 오류의 검출을 통한 오류 검출(Avaianche, Valgrind 등)한다.
- 메모리 릭(Leak), 동기화 오류 등을 분석하는 것이 가능하다. |
① static (정적 분석) , ② dynamic (동적 분석)
5. 테스트 도구의 선정
- 테스트 활용에 따른 도구 분류
| 테스트 활동 | 테스트 도구 | 설명 |
| 테스트 계획 | 요구사항 관리 | 고객 요구사항 정의 및 변경사항 관리 |
| 테스트 분석 및 설계 |
테스트 케이스 생성 | 테스트 기법에 따른 테스트 데이터 및 테스트 케이스 작성 |
| 커버리지 분석 | 대상 시스템에 대한 테스트 완료 범위 척도 | |
| 테스트 수행 | 테스트 자동화 | 기능 테스트 등 테스트 도구를 활용하여 자동화를 통한 테스트의 효율성을 높일 수 있음 (xUnit, STAF, NTAF 등) |
| 정적 분석 | 원시 코드를 분석하여 잠재적인 오류를 분석하며, 코딩 표준, 런타임 오류 등을 검증 | |
| 동적 분석 | 프로그램 수행 중 발생하는 오류의 검출을 통한 오류 검출(Avanlanche Valgrind 등) | |
| 성능 테스트 | 가상 사용자를 인위적으로 생성하여 시스템 처리 능력 측정(JMeter, AB, OpenSTA 등) | |
| 모니터링 | 시스템 자원(CPU, Memory 등) 상태 확인 및 분석 지원 도구(Nagios, Zenoss 등) | |
| 테스트 통제 | 형상관리 | 테스트 수행에 필요한 다양한 도구 및 데이터 관리 |
| 테스트 관리 | 전반적인 테스트 계획 및 활동에 대한 관리 | |
| 결함 추적/관리 | 테스트에서 발생한 결함 관리 및 협업 지원 |
section02. 개발 환경 구축
* 기출 문제 - 2023년 3회 : 클라우드 컴퓨팅 서비스 모델
20. 다음은 클라우드 컴퓨팅 서비스 모델에 대한 설명이다. 빈칸 ①~③에 알맞은 용어를 영문 약어로 쓰시오.
| ① | - 인프라스트럭처를 서비스로 제공하는 모델 - 서비스를 개발할 수 있는 안정적인 환경과 그 환경을 이용하는 응용 프로그램을 개발할 수 있는 API까지 제공하는 서비스 |
| ② | - 플랫폼을 서비스로 제공하는 모델 - 서버, 스토리지 자원을 쉽고 편하게 이용하기 쉽게 서비스 형태로 제공하여 다른 유형의 기반이 되는 기술 |
| ③ | - 소프트웨어를 서비스로 제공하는 모델 - 주문형 소프트웨어라고도 하며 사용자는 시스템이 무엇으로 이루어져 있고 어떻게 동작하는지 알 필요가 없이 단말기 등에서 필요하면 언제든지 제공받을 수 있음 |
(1) : IaaS
(2) : PaaS
(3) : SaaS
1. 클라우드 컴퓨팅(Cloud Computing)
- 클라우드 컴퓨팅은 인터넷을 통해 가상화된 컴퓨터 시스템 자원을 요구하는 즉시 처리하여 제공하는 기술이다.
- 클라우드 컴퓨팅 서비스 모델
| IaaS (Infrastructure as a Service) |
- 인프라스트럭처를 서비스로 제공하는 모델, 인프라 기본 서비스 - 서비스를 개발할 수 있는 안정적인 환경과 그 환경을 이용하는 응용 프로그램을 개발할 수 있는 API까지 제공하는 서비스 |
| PaaS (Platform as a Service) |
- 플랫폼을 서비스로 제공하는 모델, 플랫폼 기반 서비스 - 서버, 스토리지 자원을 쉽고 편하게 이용하기 쉽게 서비스 형태로 제공하여 다른 유형의 기반이 되는 기술 |
| SaaS (Software as a Service) |
- 소프트웨어를 서비스로 제공하는 모델, 소프트웨어 기반 서비스 - 주문형 소프트웨어라고도 하며 사용자는 시스템이 무엇으로 이루어져 있고 어떻게 동작하는지 알 필요가 없이 단말기 등에서 필요하면 언제든지 제공받을 수 있음 |
* 기출 문제 - 2020년 2회 : 형상관리 , 2020년 3회 : 형상통제
04. 다음 빈 칸 안에 공통으로 들어갈 가장 적합한 용어를 쓰시오.
|
: 형상관리, Software Configuration Management
01. 형상 통제에 대해 간략히 설명하시오.
: 소프트웨어 형상 변경 요청을 검토하고 승인하여 현재의 베이스라인에 반영될 수 있도록 통제
2. 형상관리(SCM, Sofrware Configuration Management)
- 소프트웨어의 개발 과정에서 발생하는 산출물의 변경 사항을 버전 관리하기 위한 일련의 활동
- 소프트웨어의 생산물을 확인하고 소프트웨어 통제, 변경 상태를 기록하고 보관하는 일련의 관리 작업
- 소프트웨어에서 일어나는 수정이나 변경을 알아내고 제어하는 것을 의미한다.
- 소프트웨어 개발의 전체 비용을 줄이고, 개발 과정의 여러 방해 요인이 최소화되도록 보증하는 것을 목적으로 한다.
- 형상관리의 절차 : 형상 식별 → 형상 통제 → 형상 감사 → 형상 기록
- 형상 통제
- 형상에 대한 변경 요청이 있을 경우 변경 여부와 변경 활동을 통제하는 것을 말한다.
- 변경된 요구사항에 대한 타당성을 검토하여 변경을 실행(변경관리)하고, 그에 따라 변경된 산출물에 대한 버전관리를 수행하는 것이 형상 통제의 주요 활동이다.
- 즉, 형상 통제는 소프트웨어 형상 변경 요청을 검토 승인하여 현재의 베이스라인(Base-line)에 반영될 수 있도록 통제하는 것을 의미한다.
- 형상 통제
Chapter02. 공통 모듈 구현하기
section01. 모듈화
1. 모듈과 모듈화
- 모듈(Module)은 하나의 프로그램을 몇 개의 작은 부분으로 분할한 몇 개의 작은 부분으로 분할한 단위이다. 즉, 독립적으로 재활용될 수 있는 소프트웨어의 부분을 말한다. 모듈의 독립성은 응집도와 결합도에 의해 측정된다.
- 모듈화(Modularity)는 시스템을 분해하고 추상화하여 소프트웨어 성능을 향상시키고 시스템의 디버깅, 테스트, 유지보수 등을 편리하게 하는 설계 과정이다.
* 기출 문제 - 2020년 1회 , 2022년 2회 : Fan-In, Fan-Out
05. 다음은 어떤 프로그램의 구조를 나타낸다. Fan-in의 수가 2 이상인 모듈의 이름을 쓰시오.

: F, H
07. 다음 주어진 구조에서 C의 Fan-In 과 Fan-Out을 구하시오.

Fan-In 1, Fan-Out 2
2. 소프트웨어 구조
- 소프트웨어 구조는 소프트웨어의 구성요소인 모듈 간의 관계를 계층적 구성을 나타낸 것이다.
- 소프트웨어 구조에서 사용되는 용어
| Fan-In | 주어진 한 모듈을 제어하는 상위 모듈 수, 들어오는 개수 |
| Fan-Out | 주어진 한 모듈이 제어하는 하위 모듈 수, 나가는 개수 |
| Depth | 최상위 모듈에서 주어진 모듈까지의 깊이 |
| Width | 같은 등급(Level)의 모듈 수 |
| Superordivate | 다른 모듈을 제어하는 모듈 |
| Subordinate | 어떤 모듈에 의해 제어되는 모듈 |
* 기출 문제 - 2020년 1회, 2021년 2회 : 응집도
04. 프로그램 모듈화와 모듈의 독립성에 대한 설명이다. 아래 ①, ②에 해당하는 용어를 쓰시오.
|
: ① 결합도(Coupling) , ② 응집도(Cohesion)
09. 다음 ①, ②, ③에 설명하는 알맞은 답안을 쓰시오.
|
① 절차적 응집도 , ② 통신적(교환적) 응집도 , ③ 기능적 응집도
3. 소프트웨어 모듈 응집도
- 응집도(Cohesion)
- 모듈 안의 요소들이 서로 기능적으로 관련되어 있는 정도
- 응집도가 강할수록 높은 품질의 모듈이다.
- 응집도 유형
| 기능적 (Functional) |
모듈 내부의 모든 기능 요소들이 한 문제와 연관되어 수행되는 경우 | 응집도 강함 |
| 순차적 (Sequential) |
한 모듈 내부의 한 기능요소에 의한 출력 자료가 다음 기능 요소의 입력 자료로 제공되는 경우 | |
| 통신적 (Communication) |
동일한 입력과 출력을 사용하는 소작업들이 모인경우 | |
| 절차적 (Procedural) |
모듈이 다수의 관련 기능을 가질 때 모듈 내부의 기능 요소들이 그 기능을 순차적으로 수행할 경우 | |
| 시간적 (Temporal) |
특정 시간에 처리되는 여러 기능을 모아 한 개의 모듈로 작성할 경우 | |
| 논리적 (Logical) |
유사한 성격을 갖거나 특정 형태로 분류되는 처리 요소들로 하나의 모듈이 형성되는 경우 | |
| 우연적 (Coincidental) |
모듈 내부의 각 기능 요소들이 서로 관련이 없는 요소로만 구성된 경우 | 응집도 약함 |
* 기출 문제 - 2020년 1회, 2021년 1회, 3회 : 결합도
04. 프로그램 모듈화와 모듈의 독립성에 대한 설명이다. 아래 ①, ②에 해당하는 용어를 쓰시오.
|
: ① 결합도(Coupling) , ② 응집도(Cohesion)
09. 다음 ①~③에서 설명하는 결합도를 작성하시오.
|
( ① ) : 모듈 간의 인터페이스로 배열이나 오브젝트, 스트럭처 등이 전달되는 경우의 결합도
( ② ) : 한 모듈이 다른 모듈 내부에 있는 지역 변수나 기능을 참조(참조 또는 수정)하는 경우의 결합도 ( ③ ) : 파라미터가 아닌 모듈 밖에 선언되어 있는 전역 변수를 참조하고 전역 변수를 갱신하는 식으로 상호 작용하는 경우의 결합도 |
: ① 스탬프 결합도 , ② 내용 결합도 , ③ 공통 결합도
04. 어떤 모듈이 다른 모듈의 내부 논리 조작을 제어하기 위한 목적으로 제어신호를 이용하여 통신하는 경우이며, 하위 모듈에서 상위 모듈로 제어신호가 이동하여 상위 모듈에게 처리 명령을 부여하는 권리 전도현상이 발생하게 되는 결합도를 무엇이라 하는지 영문으로 쓰시오.
control (coupling)
4. 소프트웨어 모듈 결합도
- 결합도(Coupling)
- 두 모듈 간의 상호 의존도
- 모듈 간의 결합도를 약하게 하면 모듈 독립성이 향상되어 시스템을 구현하고 유지보수 작업이 쉽다.
- 즉, 결합도가 낮을수록 높은 품질의 모듈이다.
- 결합도 유형
| 자료 (Data) |
- 모듈 간의 인터페이스가 자료 요소로만 구성된 경우 - 모듈 간의 인터페이스로 값이 전달되는 경우 |
결합도 약함 |
| 스탬프 (Stamp) |
- 두 모듈이 동일한 자료 구조를 조회하는 경우 - 모듈 간의 인터페이스로 배열이나 오브젝트, 스트럭처 등이 전달되는 경우 |
|
| 제어 (Control) |
- 어떤 모듈이 다른 모듈의 내부 논리 조작을 제어하기 위한 목적으로 제어신호를 이용하여 통신하는 경우 - 하위 모듈에서 상위 모듈로 제어신호가 이동하여 상위 모듈에게 처리 명령을 부여하는 권리 전도현상이 발생함 |
|
| 외부 (External) |
어떤 모듈에서 외부로 선언한 변수(데이터)를 다른 모듈에서 참조할 경우 | |
| 공통 (Common) |
여러 모듈이 공통 자료 영역을 사용하는 경우 | |
| 내용 (Content) |
한 모듈이 다른 모듈의 내부 기능 및 그 내부 자료를 조회하도록 설계되었을 경우 | 결합도 강함 |
section02. 재사용과 공통 모듈
Chapter03. 서버 프로그램 구현하기
section01. 소프트웨어 프로세스
section02. 서버 프로그램
1. 프레임워크(Framework)
2. 데이터 저장 계층 또는 영속 계층(Persistence Layer)
3. 소프트웨어(SW) 개발 보안
4. 서버 프로그램 구현 절차
* 기출 문제 - 2020년 1회 : 살충제 패러독스
03. 소프트웨어 테스트 방법의 원리 중 하나인 살충제 패러독스(Pesticide Paradox)의 개념을 간략히 설명하시오.
: 동일한 테스트 케이스로 동일한 절차를 반복 수행하면 새로운 결함을 찾을 수 없다.
5. 서버 프로그램 테스트
- 소프트웨어 테스트
- 구현된 애플리케이션이나 시스템이 사용자의 요구사항을 만족시키는지 확인하기 위하여 기능 및 비기능 요소의 결함을 찾아내는 활동
- 소프트웨어 테스트의 원칙
- 자신이 개발한 프로그램 및 소스코드를 테스팅하지 않는다.
- 테스팅은 결함이 존재함을 밝히는 활동이다.
- 완벽한 테스팅은 불가능하다.
- 테스팅은 개발 초기에 시작해야 한다.
- 결함 집중(파레토 법칙)
- 살충제 패러독스
- 동일한 테스트 케이스로 동일한 절차를 반복 수행하면 새로운 결함을 찾을 수 없다는 것을 의미한다.
- 잠재된 수많은 결함을 발견하기 위해서는 테스트 케이스를 정기적으로 개선하는 것이 필요하다는 원리이다.
- 같은 테스트 케이스를 가지고 테스트를 계속해서 반복하면 내성으로 인해 결국은 버그가 발견되지 않는다.
- 이러한 현상을 방지하기 위해서는 테스터가 적극적인 자세를 가지고 지속적으로 테스트 케이스를 검토하고 개선해야 한다.
- 테스팅은 정황(context)에 의존한다.
- 오류-부재의 궤변
section03. 배치 프로그램
[2. 프로그래밍 언어 활용] - 코드랑 같이 봐야하므로 기출 생략
Chapter01. 기본문법 활용하기
section01. C언어와 Java언어의 기본문법 구조
1. C언어와 Java언어의 개요
2. C언어의 기본 구조
3. Java언어의 기본 구조
4. C언어와 Java언어의 기본 소스코드 비교
5. C언어와 Java언어의 프로그램 구성요소
6. C언어 기본문법 구조와 prinft() 함수
- 출력형식 변환 문자
| %d | 10진 정수로 변환하여 출력 |
| %f | 부동소수점을 실수로 변환하여 출력 |
| %c | 한 문자로 변환하여 출력 |
| %s | 문자열로 변환하여 출력 |
7. Java의 System.out.print()와 System.out.println()
section02. 데이터 타입
1. 데이터 타입(Data Type, 자료형)의 정의
2. 데이터 타입의 분류
3. 기본 데이터 타입
4. 구조적 데이터 타입
5. 프로그래밍 언어의 기본 데이터 타입(Primitive Type) 및 크기
section03. 변수와 상수
1. 상수(Constant)의 개념
2. C 프로그램의 상수
3. 변수(Variable)
4. 변수의 선언문
5. 변수의 대입문 및 초기화
6. 변수와 C언어의 scanf() 함수
section04. 연산자
1. 연산자(Operator)와 우선순위
2. 이항 연산자의 우선순위
3. 산술 연산자
4. 관계 연산자
5. 논리 연산자
6. 대입 연산자와 증감 연산자
7. 삼항 연산자(조건 연산자)
8. 비트 연산자와 기타 연산자
section05. 데이터 입력 및 출력
1. 데이터 입·출력
2. C언어 대표 표준 데이터 입·출력 함수
3. C언어 데이터 입·출력 변환문자
4. C언어 확장문자(이스케이프 시퀀스, Escape Sequence)
5. C언어 데이터 입·출력 예제
section06. 제어문(1) - 선택문
1. 구조적 프로그램에서의 순서 제어
2. 제어문
3. 단순 if 문
4. if~else문과 조건 연산자
5. 다중 if문
6. switch~case문
section07. 제어문(2) - 반복문
1. while문
2. do~while문
3. for문
4. break문
5. continue문
6. goto문
section08. 배열과 문자열
1. 배열(array) 변수
2. 1차원 문자 배열과 문자열 배열
3. 2차원 배열
4. Java 언어의 자료형
5. Java 언어의 배열
6. Java 언어의 문자열
7. Java 언어의 문자열과 + 연산자
section09. C언어 포인터
1. C언어 포인터의 개요
2. 포인터 변수의 선언과 대입
3. 포인터 변수와 관련 연산자
section10. C언어 사용자 정의 함수
1. 부 프로그램
2. 프로그래밍 언어의 유해 요소
3. C언어의 사용자 정의 함수
4. 부 프로그램 되부름(재귀 호출)
section11. Java 클래스와 메소드
1. 클래스와 객체
2. 메소드 간의 호출
3. 메소드 오버로딩(Overloading)
section12. Java 상속
1. 상속(Inheritance)의 개념
2. 오버라이딩(Overriding)
section13. 예외 처리
1. 예외(Exception)의 개념
2. Java에서의 에러(오류)와 예외
3. Java에서의 예외 처리 구문
4. Java에서의 예외 처리
5. Java의 주요 예외 클래스
6. Java의 예외 처리 사례
section14. Python에 대한 이해
1. 파이썬(PYTHON)
2. Python 기본 문법 구조
3. Python 기본 자료형
4. Python 연산자
5. 시퀀스 & 셋 & 딕셔너리
6. Python 표준 입·출력
7. Python 제어문
8. Python 함수
[3. 응용 SW 기초 기술 활용]
Chapter01. 운영체제 기초 활용하기
section01. 운영체제의 개요
1. 운영체제의 개념
- 운영체제(OS, Operating System)는 컴퓨터 사용자와 컴퓨터 하드웨어 간의 인터페이스로서 동작하는 시스템 소프트웨어의 일종
2. 운영체제의 목적(= 운영체제의 성능 평가 항목)
3. 운영체제의 기능
4. 운영체제의 운영 방식
section02. 주 메모리 관리
1. 기억장치의 분류
2. 기억장치의 특징
3. 기억장치의 관리 전략
4. 배치(Placement) 전략
5. 단편화
section03. 가상 메모리 관리
1. 가상 메모리
2. 매핑 테이블
* 기출 문제 - 2024년 1회 : 페이지 교체 알고리즘(LRU, LFU)
9. 다음의 운영체제 페이지 순서를 참고하여 할당된 프레임의 수가 3개일 때 LFU와 LFU 알고리즘의 페이지 부재 횟수를 작성하시오.
| 페이지 참조 순서 : 1, 2, 3, 1, 2, 4, 1, 2, 5, 7 |
(1) LRU : 6
(2) LFU : 6
3. 페이지 교체 알고리즘
- 프로세스 실행 시 페이지 부재(Page Fault) 발생 시 가상기억장치의 페이지를 주기억장치에 적재해야 하는데, 이때 주기억장치의 모든 페이지 프레임이 사용 중이면 어떤 페이지 프레임을 교체할 지 결정하는 기법이다.
- 교체 알고리즘의 종류
| OPT (OTPimal page relpacement) |
- 이후에 가장 오랫동안 사용되지 않을 페이지를 먼저 교체하는 기법 - 실현 가능성이 희박함 |
| FIFO (First In First Out) |
- 가장 먼저 적재된 페이지를 먼저 교체하는 기법 - 벨레이디의 모순(Belady's Anomaly) 현상이 발생함 |
| LRU (Least Recently Used) |
가장 오랫동안 사용되지 않았던 페이지를 먼저 교체하는 기법 |
| LFU (Least Requently Used) |
참조된 횟수가 가장 적은 페이지를 먼저 교체하는 기법 |
| NUR (Not Used Recently) |
- 최근에 사용하지 않은 페이지를 먼저 교체하는 기법 - 매 페이지마다 두 개의 하드웨어 비트(참조 비트, 변형 비트)가 필요함 |
| SCR (Second Chance Replacement) |
각 페이지에 프레임을 FIFO 순으로 유지하면서 LRU 근사 알고리즘처럼 참조 비트를 갖게 하는 기법 |
- 페이지 부재(Page Fault)
- 참고할 페이지가 주기억장치에 없는 현상이다.
- 페이지 부재율(Page Fault Rate)에 따라 주기억장치에 있는 페이지 프레임의 수를 늘리거나 줄여 페이지 부재율을 적정 수준으로 유지하는 것이 바람직하다.
4. 가상기억장치 관련 기타 주요 용어
section04. 프로세스 스케줄링
1. 프로세스(Process)의 개념
2. 프로세스 제어 블록(PCB, Process Control Block)
* 기출 문제 - 2020년 4회
10. 다음 프로세스 상태 전이도의 빈 칸 ①~③에 알맞은 프로세스 상태를 각각 쓰시오.


: ① 준비(Ready) , ② 실행(Run) , ③ 대기(Wait 혹은 Block)
3. 프로세스 상태 전이
- 준비(Ready) 상태
- 프로세스가 준비 큐에서 실행을 준비하고 있는 상태로 CPU를 할당받기 위해 기다리고 있는 상태를 말한다.
- 실행(Running) 상태
- 준비 큐에 있는 프로세스가 CPU를 할당받아 실행되는 상태로 CPU 스케줄러에 의해 수행된다.
- 대기(Block) 상태
- 프로세스가 입/출력 처리가 필요하면 현재 수행 중인 프로세스가 입/출력을 위해 대기 상태로 전이된다.
- 대기 중인 상태의 프로세스는 입/출력 처리가 완료되면 대기 상태에서 준비 상태로 전이된다.
4. 스레드(Thread)의 개념
5. 프로세스 스케줄링
- 프로세스의 생성 및 실행에 필요한 시스템의 자원을 해당 프로세스에 할당하는 작업을 말한다.
- 스케줄링의 기법은 비선점 기법과 선점 기법으로 구분할 수 있다.
* 기출 문제 - 2020년 1회 : HRN, 2022년 3회 : SJF
11. HRN(Highest Response-ratio Next) 우선순위를 결정하는 계산식을 쓰시오.
: ( 대기시간 + 실행시간 ) / 실행시간. 이때 실행시간 대신 서비스시간도 가능.
07. 다음은 프로세스 스케줄링에 관련된 내용이다. 괄호에 맞는 답을 작성하시오.
|
( ① ) : 선점형 스케줄링 기법으로 CPU 점유 시간이 가장 짧은 프로세스에 CPU를 먼저 할당하는 방식
( ② ) : 시간단위(Time Quantum/Slice)를 정해서 프로세스를 순서대로 CPU를 할당하는 방식 ( ③ ) : 비 선점형 스케줄링 기법으로 실행시간이 가장 짧은 프로세스에게 CPU를 할당하는 방식 |
① SRT (Shortest Remaining Time) , ② Round Robin , ③ SJF (Shorteset Job First)
6. 비선점(Non-preemptive) 스케줄링 종류
- 일단 CPU를 할당받으면 다른 프로세스가 CPU를 강제적으로 빼앗을 수 없는 방식
- 모든 프로세스에 대한 공정한 처리가 가능하다.
- 일괄 처리 시스템에 적합하다.
| FCFS (First Come First Service) |
준비상태 큐에 도착한 순서대로 CPU를 할당하는 기법 - 평균 대기시간, 최대/최소 평균 반환시간 |
| SJF (Shortest Job First) |
- 준비상태 큐에서 대기하는 프로세스들 중에서 실행 시간이 가장 짧은 프로세스에게 먼저 CPU를 할당하는 기법 - 평균 대기 시간을 최소화함 - 평균 실행시간, 평균 대기시간, 평균 반환시간 |
| HRN (Highest Response-ratio Next) |
- 어떤 작업이 서비스 받을 시간과 그 작업이 서비스를 기다린 시간으로 결정되는 우선순위에 따라 CPU를 할당하는 기법 - 우선순위 계산식 = ( 대기시간 + 서비스시간 ) / 서비스시간 |
| 기한부 (Deadline) |
작업이 주어진 특별한 시간이나 만료시간 안에 완료되도록 하는 기법 |
| 우선순위 (Priority) |
- 준비상태 큐에서 대기하는 프로세스에게 부여된 우선순위가 가장 높은 프로세스에게 먼저 CPU를 할다하는기법 - 에이징(Aging) 기법 : 프로세스가 자원을 기다리고 있는 시간에 비례하여 우선순위를 부여함으로써 무기한 문제를 방지하는 기법 |
* 기출 문제 - 2022년 3회 : RR, SRT
07. 다음은 프로세스 스케줄링에 관련된 내용이다. 괄호에 맞는 답을 작성하시오.
|
( ① ) : 선점형 스케줄링 기법으로 CPU 점유 시간이 가장 짧은 프로세스에 CPU를 먼저 할당하는 방식
( ② ) : 시간단위(Time Quantum/Slice)를 정해서 프로세스를 순서대로 CPU를 할당하는 방식 ( ③ ) : 비 선점형 스케줄링 기법으로 실행시간이 가장 짧은 프로세스에게 CPU를 할당하는 방식 |
① SRT (Shortest Remaining Time) , ② Round Robin , ③ SJF (Shorteset Job First)
7. 선점(Preemptive) 스케줄링
- 한 프로세스가 CPU를 할당받아 실행 중이라도 우선순위가 높은 다른 프로세스가 CPU를 강제적으로 빼앗을 수 있는 방식
- 긴급하고 높은 우선순위의 프로세스들이 빠르게 처리될 수 있다.
- 대화식 시분할 시스템에 적합하다.
| SRT (Shortest Remaining Time) |
- 실행 중인 프로세스의 남은 시간과 준비상태 큐에 새로 도착한 프로세스의 실행 시간을 비교하여 실행 시간이 더 짧은 프로세스에게 CPU를 할당하는 기법 - 시분할 시스템에 유용함 - 평균 반환시간(최종 완료 시간 - 도착 시간) 그림그리기! |
| RR (Round Robin) |
- 주어진 시간 할당량 안에 작업을 마치지 않으면 준비완료 리스트의 가장 뒤로 배치되는 기법 - 시간 할당량이 너무 커지면 FCFS와 비슷하고, 시간 할당량이 너무 작아지면 오버헤드가 커지게 됨 - 사용 순서, 평균 대기시간, 평균 반환시간(대기시간을 먼저 구한 후, 대기시간+실행시간/개수) |
| 다단계 큐 (MQ, Multi-level Queue) |
프로세스들을 우선순위에 따라 시스템 프로세스, 대화형 프로세스, 일괄처리 프로세스 등으로 상위, 중위, 하위 단계의 단계별 준비 큐를 배치하는 방법 |
| 다단계 피드백 큐 (MFQ, Multi-lever Feedback Queue) |
- 각 준비상태 큐마다 부여된 시간 할당량 안에 완료하지 못한 프로세스는 다음 단계의 준비상태 큐로 이동하는 기법 - 짧은 작업, 입/출력 위주의 작업 권에 우선권을 부여함 - 마지막 단계의 큐에서는 작업이 완료될 때까지 RR 방식을 취함 |
8. 병행 프로세스
9. 교착 상태(DeadLock)
section05. 환경변수
1. 환경변수(Environment Variable)의 개념
2. 환경변수의 확인
3. Windows 환경변수의 확인
4. Windows 주요 환경변수
5. UNIX/LINUX 주요 환경변수
6. Windows에서 Java 실행 관련 PATH 환경변수 확인
section06. 운영체제의 종류 및 Shell Script
1. 운영체제의 종류
2. UNIX의 개요
3. UNIX의 파일 시스템
4. UNIX의 주요 명령어 - chmod
5. Shell script
Chapter02. 데이터베이스 개념
section01. 데이터베이스 개념
1. 데이터베이스 정의
2. 데이터베이스의 특징
3. 데이터베이스의 구성요소
section02. 데이터베이스 관리 시스템
1. DBMS(DataBase Management System)의 정의
2. DBMS의 필수 기능
3. DBMS의 장·단점
4. 데이터베이스 언어
section03. 데이터베이스 구조(스키마)
1. 데이터베이스의 표현
* 기출 문제 - 2020년 3회, 2023년 1회
09. 데이터베이스 스키마(Schema)에 대해 간략히 서술하시오.
: 데이터베이스의 전체적인 구조와 제약조건에 대한 명세를 기술하고 정의한 것이다.
2. 스키마(Schema)

- 스키마는 데이터베이스의 전체적인 구조와 제약조건에 대한 명세를 기술·정의한 것을 말하며, 스킴(Scheme)이라고도 한다.
- 스키마의 종류
- 내부 스키마(Internal Schema) : 물리적 저장 장치 관점(기계 관점)에서 본 데이터베이스의 물리적 구조
- 개념 스키마(conceptual Schema) : 논리적 관점(사용자 관점에서 본 전체적인 데이터 구조
- 외부 스키마(External Schema) : 전체 데이터 중 사용자가 사용하는 한 부분에서 본 논리적 구조를 말하며, 서브 스키마라고도 함
3. 데이터베이스 관리자(DBA, DataBase Administrator)
Chapter03. 데이터베이스 설계
section01. 데이터베이스 설계
1. 요구 조건 분석
* 기출 문제 - 2020년 2회
02. 다음은 데이터베이스 설계의 순서이다. 빈 칸에 해당하는 설계 순서를 쓰시오.
|
요구사항 분석 → ( ) → ( ) → ( ) → 구현
|
: 개념적 설계, 논리적 설계, 물리적 설계
2. 설계
- 개념적 데이터 설계
- 구축하고자 하는 데이터베이스를 개념적으로 표현함으로써 구현할 데이터베이스를 정하고, 데이터베이스를 구성할 구성요소를 결정한 후 수행할 작업과 관계를 설정하는 과정
- DBMS 독립적 개념 스키마 설계, 트랜잭션 모델링 및 정의
- ERD
- 논리적 데이터 설계
- 개념적 설계에서 만들어진 구조를 논리적으로 구현 가능한 모델로 변환하는 단계
- 목표 DBMS에 맞는 스키마 설계, 트랜잭션 인터페이스 설계
- 정규화
- 물리적 데이터 설계
- 논리적 데이터베이스 구조를 실제 기계가 처리하기에 알맞도록 내부 저장 장치 구조와 접근 경로 등을 설계하는 과정
- 목표 DBMS에 맞는 물리적 구조 설계, 트랜잭션 세부 설계
- 성능 고려, 반정규화
3. 구현
4. 운영 및 유지보수
section02. 개체-관계 모델(E-R Model)
1. 개체-관계 모델
- 데이터베이스를 구성하는 개체(Entity) 타입과 관계(Relationship) 타입 간의 구조 또는 개체를 구성하는 속성(Attribute) 등을 약속된 기호를 이용하여 표현함으로써 데이터베이스의 전반적인 구조를 이해하기 쉽도록 표현한 모델
2. E-R Model의 기호

3. E-R Model의 표현
4. 다양한 관계 표현법(정보 공학적 표현법)
5. 데이터베이스 모델
section03. 관계 데이터 모델
1. 관계 데이터 모델의 개념
- 릴레이션(Relation) : 릴레이션 스팀과 릴레이션 인스턴스로 구성된다.
- 릴레이션 스킴(Scheme) : 릴레이션의 구조이다.
- 릴레이션 인스턴스(Instance) : 어느 한 시점에 릴레이션이 포함하고 있는 튜플의 집합이다.
- 속성(Attribute) : 데이터의 가장 작은 논리적 단위로서 파일 구조상의 데이터 항목 또는 데이터 필드에 해당한다.
- 튜플(Tuple) : 테이블의 행(Row)에 해당하며 파일 구조의 레코드(Recode)와 같은 의미이다.
- 디그리(Degree) : 속성의 개수이다.
- 카디널리티(Cardinality) : 튜플의 개수(기수)이다.
- 도메인(Domain) : 속성이 취할 수 있는 값들의 집합이다.
2. E-R Model과 관계 데이터 모델과의 관계
section04. 키(KEY)와 무결성 제약조건
1. 키(Key)의 개념
2. 키(Key)의 종류
* 기출 문제 - 2023년 3회 : 참조 무결성
16. 다음 설명하는 빈칸에 알맞은 용어를 쓰시오.
| 릴레이션 무결성 제약조건은 릴레이션을 조작하는 과정에서의 의미적 관계(Semantic Relationship)를 명세한 것으로 정의 대상으로 도메인, 키, 종속성 등이 있다. 그 중 ( ) 무결성 제약조건은 릴레이션 R1에 속성 조합인 외래키를 변경하려면 이를 참조하고 있는 릴레이션 R2의 기본키도 변경해야 한다. 이때 참조할 수 없는 외래키 값을 가질 수 없다는 제약조건이다. |
참조
3. 무결성(Intergrity) 제약조건
- 개체 무결성 제약조건
- 기본키는 NULL 값을 가져서는 안되며, 릴레이션 내에 오직 하나의 값만 존재해야 한다는 제약조건
- 참조 무결성 제약조건
- 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없음을 의미하는 제약 조건
- 도메인 무결성 제약조건
- 릴레이션 내의 튜플들이 각 속성의 도메인에 정해진 값만을 가져야 한다는 제약 조건
section05. 관계 데이터 연산
* 기출 문제 - 2022년 3회, 2023년 3회
12. 다음 항목에 맞는 관계대수 기호를 작성하시오.
| 항목 | 기호 |
| 합집합 | A ( ∪ ) B |
| 차집합 | A ( - ) B |
| 카티션 프로덕트 | A ( × ) B |
| 프로젝트 | A ( π ) B |
| 조인 | A ( ⋈ ) B |
15. 다음 설명에 해당하는 관계 대수 연산기호를 빈칸 ①~④에 각각 <보기>에서 골라 쓰시오.
| ( ① ) | 공통 속성을 기준으로 두 릴레이션을 합하여 새로운 릴레이션을 만드는 연산 |
| ( ② ) | 속성 리스트로 주어진 속성만 구하는 수직적 연산 |
| ( ③ ) | 조건에 맞는 튜플을 구하는 수평적 연산 |
| ( ④ ) | 두 릴레이션 R1, R2에 대해 릴레이션 R2의 모든 조건을 만족하는 튜플들을 릴레이션 R1에서 분리해 내어 프로젝션하는 연산 |
| ㄱ. ∪ ㄴ. σ ㄷ. ∩ ㄹ. π ㅁ. - ㅂ. ⋈ ㅅ. × ㅇ. ÷ |
(1) : ㅂ
(2) : ㄹ
(3) : ㄴ
(4) : ㅇ
1. 관계 대수(Relational Algebra)
- 관계 대수는 릴레이션에서 사용자가 원하는 결과를 얻기 위해 연산자를 표현하는 방법으로 결과를 얻기 위한 절차를 표현하기 때문에 절차적 언어라고 한다.
- 원하는 정보와 그 정보를 어떻게 유도하는가를 기술하는 절차적인 방법
- 관계 대수는 크게 순수 관계 연산자와 일반 집합 연산자로 나뉜다.
| 구분 | 연산자 | 기호 | 의미 |
| 순수 관계 연산자 |
Select | σ | 조건에 맞는 튜플을 구하는 수평적 연산 |
| Project | π | 속성 리스트로 주어진 속성만 구하는 수직적 연산 | |
| Join | ⋈ | 공통 속성을 기준으로 두 릴레이션을 합하여 새로운 릴레이션을 만드는 연산 | |
| Division | ÷ | 두 릴레이션 A, B에 대해 B 릴레이션의 모든 조건을 만족하는 튜플들을 릴레이션 A에서 분리해 내어 프로젝션하는 연산 | |
| 일반 집합 연산자 |
합집합 | ∪ | 두 릴레이션의 튜플의 합집합을 구하는 연산 |
| 교집합 | ∩ | 두 릴레이션의 튜플의 교집합을 구하는 연산 | |
| 차집합 | - | 두 릴레이션의 튜플의 차집합을 구하는 연산 | |
| 교차곱 | × | 두 릴레이션의 튜플들의 교차곱(순서쌍)을 구하는 연산 |
* 기출 문제 - 2022년 2회
01. 다음 공통으로 설명하는 빈칸에 알맞은 용어를 쓰시오.
|
관계해석
2. 관계 해석(Relational Calculus)
- 관계 해석은 릴레이션에서 결과를 얻기 위한 과정을 표현하는 것으로 연산자 없이 정의하는 방법을 이용하는 비절차적 언어이다.
- 튜플 관계 해석과 도메인 관계 해석이 있다.
Chapter04. 데이터베이스 활용
section01. 이상(Anomaly)과 함수적 종속
* 기출 문제 - 2020년 4회
08. 데이터베이스에서 릴레이션을 처리하는 데 여러 문제를 초래하는 이상 현상 3가지를 쓰시오.
: 삽입 이상, 삭제 이상, 갱신 이상
03. 데이터베이스의 이상현상 중, 삭제 이상에 대해 간략히 서술하시오.
: 한 튜플을 삭제할 때 연쇄 삭제 현상으로 인해 정보 손실 (흥달쌤)
: 튜블 삭제 시 의도와는 상관없이 관련 없는 데이터가 같이 연쇄 삭제(Triggered Deletion)되어 정보의 손실이 발생하는 현상을 의미한다. (이기적)
1. 이상(Anomaly)
- 데이터 베이스의 논리적 설계 시 하나의 릴레이션에 많은 속성들이 존재하여, 데이터의 중복과 종속으로 인해 발생되는 문제점을 말한다. 이상 현상은 릴레이션을 처리하는 데 여러 가지 문제를 초래하게 된다.
- 이상의 종류에는 삭제 이상, 삽입 이상, 갱신 이상이 있다.
- 삽입 이상 : 관계 데이터베이스에서 삽입 역시 튜플 단위로 이루어진다. 이때 삽입하는 과정에서 원하지 않는 자료가 삽입된다든지 도는 삽입하는 데 자료가 부족해 삽입이 되지 않아 발생하는 문제점을 삽입 이상이라고 한다.
- 삭제 이상 : 관계 데이터베이스에서 삭제는 튜플 단위로 이루어진다. 삭제 이상은 테이블에서 하나의 자료를 삭제하고자 하는 경우 그 자료가 포함된 튜플이 삭제됨으로 인해 원하지 않은 자료까지 함께 삭제가 이루어져 발생하는 문제점을 말한다.
- 갱신 이상 : 관계 데이터베이스의 자료를 갱신하는 과정에서 정확하지 않거나 일부의 튜플만 갱신됨으로 인해 정보가 모호해지거나 일관성이 없어져 정확한 정보의 파악이 되지 않는 현상을 말한다.
| 삽입 이상 (Insertion Anomaly) |
어떤 데이터를 삽입하려고 할 때 불필요하고 원하지 않는 데이터도 함께 삽입해야만 되고 그렇지 않으면 삽입되지 않는 현상 |
| 삭제 이상 (Deletion Anomaly) |
한 튜플을 삭제함으로 인해서 유지해야 하는 정보까지 삭제되는 연쇄 삭제 현상이 일어나게 되어 정보 손실이 발생하는 현상 |
| 수정(갱신) 이상 (Update Anomaly) |
중복된 튜플 중에 일부 튜플의 속성값만을 갱신시킴으로써 정보의 모순성(Inconsistency)이 생기는 현상 |
* 기출 문제 - 2022년 2회
14. 다음은 함수종속(Functional Dependency)과 정규화(Normalization)에 대한 설명이다. 설명에 해당하는 용어를 빈칸에 각각 <보기>에서 골라 쓰시오.
| 이상(Anomaly)과 함께 관계형 데이터베이스에서 고려해야 할 것 중에 하나가 함수종속(Functional Dependency)이다. 함수종속의 종류로는 ( ① ) Functional Dependency, ( ② ) Functional Dependency, ( ③ ) Functional Dependency 등이 있다. '고객번호', '제품번호', '제품명', '주문량'으로 구성된 <고객주문> 테이블이 있다. <고객주문> 테이블에서는 '고객번호'와 '제품번호'가 조합된 (고객번호, 제품번호)가 기본키이고 다음과 같은 함수종속 관계가 존재한다. |
| (고객번호, 제품번호) → 주문량 제품번호 → 제품명 |
| <고객주문> 테이블에서 '주문량' 속성은 기본키인 '고객번호'와 '제품번호'를 모두 알아야 구분할 수 있다. 이런 경우, '주문량' 속성은 기본키인 '고객번호'와 제품번호'를 모두 알아야 구분할 수 있다. 이런 경우, '주문량' 속성은 기본키에 ( ① ) Functional Dependency 되었다고 한다. 반면, 기본키의 일부인 '제품번호'만 알아도 '제품명'을 알 수 있다. 이와 같은 경우 '제품명'은 기본키에 ( ② ) Functional Dependency 되었다고 한다. ( ② ) Functional Dependency는 릴레이션에서 한 속성이 기본키가 아닌 다른 속성에 종속이 되거나 또는 기본키가 2개 이상의 복합키(합성키)로 구성된 경우, 이 중 일부 속성에 종속이 되는 경우를 말한다. 2NF는 1NF에서 ( ② ) Functional Dependency 로 인한 이상의 문제를 해결하이 위해 릴레이션을 분해한 정규형을 말한다. 2NF의 속성들 간에는 ( ① ) Functional Dependency 관계가 성립하게 된다. 3NF는 ( ③ ) Functional Dependency 관계가 성립하지 않도록 하는 것이다. ( ③ ) Functional Dependency란 간접적인 함수 종속관계를 의미한다. 즉, 예를 들어 속성 A가 속성 B를 결정하고, 속성 B는 속성 C를 결정하는 경우, A →C가 성립한다. 아울러 3NF에서는 결정자이면서 후보키가 아닌 것이 존재함에 따라 이상 현상이 발생할 수도 있다. 결정자이면서 모두 후보키이면, 릴레이션 R은 BCNF에 속한다. |
① Full (완전 함수 종속) , ② Partial (부분 함수 종속) , ③ Transitive (이행적 함수 종속)
2. 함수적 종속(Functional Dependency)
- 개체 내에 존재하는 속성 간의 관계를 종속적인 관계로 정리하는 방법이다.
- 데이터 속성들의 의미와 속성 간의 상호관계로부터 도출되는 제약조건이다.
| 부분 함수 종속 (Partial Functional Dependency) |
릴레이션에서 한 속성이 기본키가 아닌 다른 속성에 종속이 되거나 또는 기본키가 2개 이상 합성키로 구성된 경우 이 중 일부 속성에 종속이 되는 경우 |
| 완전 함수 종속 (Full Functional Dependency) |
릴레이션에서 한 속성이 오직 기본키에만 종속이 되는 경우 |
| 이행적 함수 종속 (Transitive Functional Dependency) |
릴레이션에서 A, B, C 세 속성 간의 종속이 A → B, B → C일 때, A → C가 성립이 되는 경우 |
section02. 정규화
1. 정규화(Normalization)
* 기출 문제 - 2021년 2회
05. 부분 함수적 종속성을 제거하여 완전 함수 종속을 만족하는 정규형이 무엇인지 쓰시오.
제 2정규형 (2NF)
2. 정규형의 종류
비정규 릴레이션
⬇️
원자값이 아닌 도메인을 분해
1NF ⬇️
부분 함수 종속 제거
2NF ⬇️
이행 함수 종속 제거
3NF ⬇️
결정자나 후보키가 아닌 함수 종속 제거
BCNF ⬇️
다치 종속성 제거
4NF ⬇️
조인 종속
5NF ⬇️
section03. 트랜잭션(Transaction)
1. 트랜잭션(Transaction)
- 데이터베이스 내에서 한꺼번에 모두 수행되어야 할 연산들의 집합으로, 하나의 작업 처리를 위한 논리적 작업 단위를 말한다.
* 기출 문제 - 2020년 1회, 2021년 2회
12. 다음은 트랜잭션(Transaction)의 주요 특성 4가지이다. 빈칸 ①, ②에 알맞은 용어를 쓰시오.
|
( ① )
|
트랜잭션의 가장 기본적인 특성으로 트랜잭션 내의 연산은 반드시 모두 수행되어야 하며 그렇지 못한 경우 모두 수행되지 않아야 함
|
|
일관성
|
트랜잭션이 정상적으로 완료된 후 언제나 일관성 있는 데이터베이스 상태가 되어야 하며, 결과에 모순이 생겨서는 안 됨
|
|
( ② )
|
하나의 트랜잭션이 수행 중에는 다른 트랜잭션이 접근할 수 없고 각각의 트랜잭션은 독립적이어야 함
|
|
영속성
|
지속성이라고도 하며, 트랜잭션이 성공적으로 완료된 후 결과는 지속적으로 유지되어야 함
|
: ① 원자성 , ② 독립성 또는 격리성
04. 데이터베이스에서 트랜잭션의 특징인 ACID 중 원자성(Atomicity)의 개념에 대하여 간략히 설명하시오.
연산의 결과는 모두 반영되거나, 모두 반영되지 않아야 한다. (Commit, Rollback)
2. 트랜잭션의 성질(ACID)
- 원자성(Atomicity)
- 완전하게 수행이 완료되지 않으면 전혀 수행되지 않아야 한다.
- 연산은 Commit, Rollback을 이용하여 적용 또는 취소로 한꺼번에 완료되어야 한다.
- 중간에 하나의 오류가 발생되더라도 취소가 되어야 한다.
- 일관성(Consistency)
- 시스템의 고정 요소는 트랜잭션 수행 전후가 같아야 한다.
- 트랜잭션 결과는 일관성을 유지해야 한다.
- 트랜잭션 처리 전과 후의 데이터베이스 상태는 같아야 한다. 처리 후라고 해서 구조나 형식이 변경되어서는 안 된다.
- 격리성(Isolation)
- 트랜잭션 실행 시 다른 트랜잭션의 간섭을 받지 않아야 한다.
- 영속성(Durability)
- 트랜잭션의 완료 결과가 데이터베이스에 영구히 기억되어야 한다.
3. 트랜잭션 연산
4. 트랜잭션의 상태도
section04. 회복 기법과 병행 제어
* 기출 문제 - 2020년 4회 : 즉시 갱신, 2022년 1회 : REDO, UNDO
09. 데이터베이스 회복 기법에 관련된 설명에서 괄호에 들어갈 가장 알맞은 용어를 쓰시오.
|
- 다양한 데이터 회복 기법 중 ( ) 회복 기법은 로그를 이용한 회복 기법으로 데이터베이스에 대한 갱신 로그를 저장함으로써 회복에 대비한다.
- ( ) 회복 기법은 트랜잭션이 실행 상태에서 변경되는 내용을 그때그때 바로 데이터베이스에 적용하는 기법이다. - ( ) 회복 기법은 장애가 발생하면 로그 파일에 기록된 내용을 참조하여, 장애 발생 시점에 따라 Redo나 Undo를 실행하여 데이터베이스를 복구한다. |
: 즉시 갱신(Immediate Update)
02. 다음은 손상된 데이터베이스를 손상되기 이전의 정상적인 상태로 복구(Recovery)시키는 과정에 대한 설명이다. 트랜잭션에 대해 검사시점(Checkpoint) 회복 기법이 사용될 때, 시스템이 장애가 발생한 후 수행하는 트랜잭션 관리 연산의 기호를 빈칸에 각각 <보기>에서 골라 쓰시오.
|
① REDO, ② UNDO
1. 회복(Recovery)
- 회복 기법
- 즉시 갱신 기법
- 트랜잭션이 실행(활동) 상태에서 변경되는 내용을 그때그때 바로 데이터베이스에 적용하는 기법
- 변경되는 모든 내용은 로그(Log)에 기록하여 장애 발생 시 로그(Log)의 내용을 토대로 회복
- Redo(재실행), Undo(취소) 모두 수행
- 검사적 회복 기법(Checkpoint Recovery)
- 트랜잭션이 실행되는 중간에 검사 시점(Check Point)을 지정하여 검사 시점까지 수행 후 완료된 내용을 데이터베이스에 적용하는 기법
- 그림자 페이징(Shadow Paging) 기법
- 로그(Log)를 사용하지 않고, 데이터베이스를 동일한 크기의 단위인 페이지로 나누어 각 페이지마다 복사하여 그림자 페이지를 보관
- 데이터베이스의 변경되는 내용은 원본 페이지에만 적용하고, 장애가 발생되는 경우 그림자 페이지를 이용해 회복
- 즉시 갱신 기법
- 트랜잭션 회복 연산

REDO
(재실행)트랜잭션이 수행되어 COMMIT이 되면 변경된 내용을 데이터베이스에 반영한다. 이때 로그(Log)의 내용을 토대로 재수행하며 변경된 내용으로 데이터베이스에 반영하는 과정 UNDO
(실행 취소)트랜잭션이 수행되는 도중 오류가 발생하거나 비정상적으로 종료되는 경우 트랜잭션이 시작된 시점으로 되돌아가 수행 연산을 취소하는 과정
* 기출 문제 - 2021년 2회 : 로킹
08. 하나의 트랜잭션이 데이터를 액세스하는 동안 다른 트랜잭션이 그 데이터 항목을 액세스할 수 없도록 하는 병행 제어 기법이 무엇인지 쓰시오.
로킹(Locking)
2. 병행 제어(Concurrency Control)
- 동시에 여러 개의 트랜잭션이 실행되는 경우를 병행 실행이라고 하는데 이와 같은 병행 실행 시 트랜잭션 간의 격리성을 유지하여 트랜잭션 수행에 문제가 발생되지 않도록 제어하는 것을 병행제어라고 한다.
- 병행제어를 하지 않았을 때의 문제점
- 갱신 분실
- 비완료 의존성
- 모순성
- 연쇄 복귀
- 병행제어 기법
- 로킹
- 로킹(Locking) 기법은 트랜잭션의 병행 실행 시 하나의 트랜잭션이 사용하는 데이터베이스 내의 데이터를 다른 트랜잭션이 접근하지 못하게 하는 것을 말한다.
- 하나의 트랜잭션이 실행될 때는 'LOCK'을 설정해 다른 트랜잭션이 데이터에 접근하지 못하도록 잠근 후 실행하고, 실행이 완료되면 'UNLOCK'을 통해 해제한다.
- LOCK → 트랜잭션 실행 → 트랜잭션 완료 → UNLOCK
- 2단계 로킹
- 타임스탬프
- 낙관적 병행제어
- 다중 버전 병행 제어
- 로킹
section05. 객체지향 데이터베이스
1. 객체지향 데이터베이스(OODB)의 등장 배경
2. 객체(Object)와 객체지향 기법의 특징
section06. 기타 데이터베이스 용어
1. 개체(Entity)의 종류
2. 속성(Attribute)의 종류
3. 관계(Relation)의 종류
4. 분산 데이터베이스(Distributed Database)
5. 튜닝(Tuning)
6. CRUD 매트릭스
7. 트리거(Trigger)
8. 내장 SQL(Embedded-SQL)
9. 스토어드 프로시저(Stored Procedure)
10. 기타 데이터베이스 용어
11. 인덱스(INDEX)
Chapter05. 네트워크 기초 활용하기
section01. 네트워크의 개요
1. 컴퓨터 네트워크(Computer Network)
2. 네트워크의 장점
3. 거리(규모)에 따른 네트워크 분류
4. LAN(Local Area Network)의 이해
* 기출 문제 - 2021년 2회, 2023년 1회, 2024년 2회 : 패킷 교환 방식
11. 다음 패킷 교환방식에 대한 설명으로 ①, ②에 알맞은 용어를 쓰시오.
|
① 가상 회선 방식(Virtual Circuit) , ② 데이터그램 방식(Datagram)
18. 다음은 패킷 교환 방식(Packet Switching)에 대한 설명이다. 빈칸 ①, ②에 알맞은 용어를 각각 쓰시오.
| 패킷 교환 방식(Packet Switching)은 패킷 교환망에서 메시지를 일정한 길이의 전송 단위인 패킷으로 나누어 전송하는 방식이다. 패킷 교환은 저장-전달 방식을 사용한다. 패킷 교환의 방식으로는 연결형인 ( ① )과 비연결형인 ( ② )의 두 가지 방식으로 구분된다. ( ① )은 패킷이 전송되기 전에 논리적인 연결 설정이 이루어져야 한다. ( ① )은 모든 패킷이 동일한 경로로 전달되므로 항상 보내어진 순서대로 도착이 보장된다. ( ① )은 연결형 서비스 방식으로 패킷을 전송하기 전에 미리 경로를 설정해야 한다. ( ② )은 일정 크기의 데이터 단위(packet)로 나누어 특정 경로의 설정 없이 전송되는 방식이며, 각 패킷마다 목적지로 가기 위한 경로 배정이 독립적으로 이루어진다. |
① 가상회선(Virtual Circuit) , ② 데이터그램(Datagram)
8. 패킷 교환 방식 중 연결형과 비연결형에 해당하는 방식을 작성하시오.
연결형 : 가상회선
비연결형 : 데이터그램
5. WAN(Wide Area Network)의 이해
- 국가, 대륙과 같이 광범위한 지역을 연결하는 네트워크
- 거리에 제약이 없으나 다양한 경로를 지나 정보가 전달되므로 LAN보다 속도가 느리고 에러율도 높다.
- 전용 회선 방식은 통신 사업자가 사전에 계약을 체결한 송신자와 수신자끼리만 데이터를 교환하는 방식이다.
- 교환 회선 방식은 공중망을 활용하여 다수의 사용자가 선로를 공유하는 방식이다.
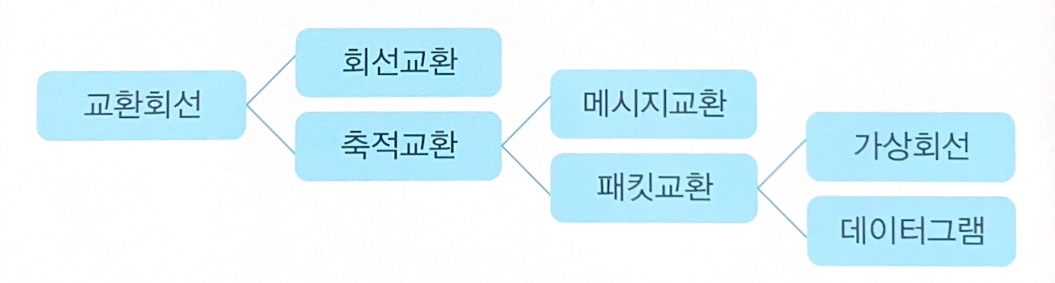
- 패킷 교환 방식(Packet Switching)
- 메시지를 일정한 길이의 전송 단위인 패킷으로 나누어 전송하는 방식이다.
- 다수의 사용자 간에 비대칭적 데이터 전송을 원할하게 하므로 모든 사용자 간에 빠른 응답 시간 제공이 가능하다.
- 전송에 실패한 패킷의 경우 재전송이 가능하다.
- 패킷 단위로 헤더를 추가하므로 패킷별 오버헤드가 발생한다.
- 현재 컴퓨터 네트워크에서 주로 사용하는 방식이며, 패킷교환공중데이터통신망(PSDN)이라고도 한다.
- 패킷 교환 방식은 축적 후 전달(Store-and-Forward) 방식이다.
- 메시지를 작은 데이터 조각인 패킷으로 블록화한다.
- 종류 : 가상 회선 방식, 데이터그램 방식
| 가상회선 (Virtual Circuit) |
- 연결형 서비스 - 데이터를 패킷 단위로 나누어 전송 - 가상 연결 설정을 통해 전송되는 모든 패킷의 경로가 동일 - 패킷의 도착 순서가 일정(출발/도착 순서 동일) |
| 데이터그램 (Datagram) |
- 비연결형 서비스 - 패킷을 독립적으로 전송(서로 다른 경로, 경로를 미리 할당하지 않음) - 정보의 양이 적거나 상대적으로 신뢰성이 중요하지 않은 환경에서 사용 - 송신 호스트가 전송한 패킷은 보낸 순서와 무관한 순서로 수신(서로 다른 경로, 네트워크 혼잡도에 따라 가변적) |
section02. 인터넷 구성의 개념
1. 인터네트워킹
2. 인터넷
3. 인터넷 주요 서비스(TCP/IP 상에서 운용됨)
4. 인터넷 주소 체계
5. IPv6
section03. OSI 7 참조 모델
1. 계층화 구조
2. PDU(Protocol Data Unit)
* 기출 문제 - 2020년 1회, 2021년 3회
13. OSI 7 참조 모델 중 다음이 설명하는 계층을 쓰시오.
|
- 전기적, 기계적, 기능적인 특성을 이용해서 통신 케이블로 데이터를 전송
- 통신 단위는 비트이며 이것은 1과 0으로 나타내어지는, 즉 전기적으로 On, Off 상태이다. - 데이터를 전달할 뿐, 데이터가 무엇인지 어떤 에러가 있는지 신경쓰지 않는다. |
: 물리 계층
13. OSI 7 Layer에 대한 설명에서 ①~③에 들어갈 알맞은 계층을 쓰시오.
|
( ① ) : 포인트 투 포인트의 신뢰성 있는 데이터 전송을 보장하며, 물리 계층의 오류를 감지하고 수정한다.
( ② ) : 데이터를 목적지까지 가장 안전하고 빠르게 전달하는 기능 ( ③ ) : 데이터 표현이 상이한 응용 프로세스의 독립성을 제공하고, 암호화 한다. |
① 데이터 링크 계층 , ② 네트워크 계층 , ③ 표현 계층
3. OSI(Open Systems Interconnection) 7 계층
| OSI 7 | 단위 | 주요 장비 | TCP / IP | |
| 응용 계층 | 메시지 | 게이트웨이 | 응용 계층 | telnet, FTP, HTTP, POP, SMTP DHCP, SNMP, DNS |
| 표현 계층 | ||||
| 세션 계층 | ||||
| 전송 계층 | 세그먼트, 데이터그램 | 전송 계층 | TCP, UDP | |
| 네트워크 계층 | 패킷 | 라우터 | 인터넷 계층 | IP, ARP, RARP, ICMP, IGMP |
| 데이터링크 계층 | 프레임 | 브리지, 스위치 | 링크 계층 | Ethernet, IEEE 802 |
| 물리 계층 | 비트 | 허브, 리피터 |
section04. 통신 프로토콜
* 기출 문제 - 2020년 3회
15. 빈 칸 안에 공통으로 들어갈 가장 적합한 용어를 쓰시오.
|
심리학자 톰 마릴은 컴퓨터가 메시지를 전달하고, 메시지가 제대로 도착했는지 확인하며, 도착하지 않았을 경우 메시지를 재전송하는 일련의 방법을 가리켜 '기술적 은어'라는 뜻으로 ( )(이)라 불렀다.
|
: 프로토콜
1. 프로토콜(Protocol)의 개념
- 둘 이상의 컴퓨터 사이에 데이터 전송을 할 수 있도록 미리 정보의 송·수신 측에서 정해둔 통신 규칙이다.
- 프로토콜의 기본 요소는 구문, 의미, 타이밍이다.
* 기출 문제 - 2020년 1회
10. 통신 프로토콜 또는 통신 규약은 컴퓨터나 원거리 통신 장비 사이에서 메시지를 주고 받는 양식과 규칙의 체계이다. 통신 프로토콜의 기본 요소 3가지를 쓰시오.
: 구문(Syntax), 의미(Semantic), 타이밍(Timing)
2. 프로토콜의 기본 요소
| 구문(Syntax) | 전송 데이터의 형식, 부호화, 신호 레벨 등을 규정함 |
| 의미(Semantic) | 전송 제어와 오류 관리를 위한 제어 정보를 포함함 |
| 타이밍(Timing) | 두 개체 간에 통신 속도를 조정하거나 메세지의 전송 및 순서도에 대한 특성을 가리킴 |
3. 통신 프로토콜의 기능
4. X.25
5. TCP/IP
6. 표준안 제정 기관
section05. TCP/IP
1. TCP/IP의 구조
| OSI 7 | 단위 | 주요 장비 | TCP / IP | |
| 응용 계층 | 메시지 | 게이트웨이 | 응용 계층 | telnet, FTP, HTTP, POP, SMTP DHCP, SNMP, DNS |
| 표현 계층 | ||||
| 세션 계층 | ||||
| 전송 계층 | 세그먼트, 데이터그램 | 전송 계층 | TCP, UDP | |
| 네트워크 계층 | 패킷 | 라우터 | 인터넷 계층 | IP, ARP, RARP, ICMP, IGMP |
| 데이터링크 계층 | 프레임 | 브리지, 스위치 | 링크 계층 | Ethernet, IEEE 802 |
| 물리 계층 | 비트 | 허브, 리피터 |
2. TCP의 개요
3. TCP 세그먼트(Segment)
4. UDP의 개요
5. UDP 데이터그램
6. 경로 설정(Routing)
7. 라우터의 주요 기능
8. 라우팅 프로토콜(Routing Protocol)
9. 라우팅 프로토콜의 비교
10. 동적 라우팅 프로토콜의 종류
* 기출 문제 - 2020년 3회, 2022년 2회, 2023년 3회
11. 다음 설명에 해당하는 라우팅 프로토콜을 쓰시오.
|
: OSPF
04. 다음은 동적 라우팅 프로토콜에 대한 설명이다. 빈칸에 해당하는 프로토콜을 각각 <보기>에서 골라 쓰시오.
| 자치 시스템(AS: Autonomous System)은 인터넷상에서 관리적 측면에서 한 단체에 속하고 관리되고 제어됨으로써, 동일한 라우팅 정책을 사용하는 네트워크 또는 네트워크 그룹을 말한다. 라우팅 도메인으로도 불리며, 전 세계적으로 유일한 자치 시스템번호, ASN(Autonomous System Number)을 부여받는다. AS 번호에 따라 ( ① )와 ( ② )로 구분한다. 동일한 AS 번호를 사용하는 라우팅 프로토콜을 ( ① ) 이라 하며, 다른 AS 번호가 사용되는 라우팅 프로토콜을 ( ② )라 한다. 한 자치 시스템 내에서의 IP 네트워크는 라우팅 정보를 교환하기 위해 내부 라우팅 프로토콜인 ( ① )을 사용한다. ( ① )의 대표적인 프로토콜로는 RIP과 ( ③ ) 가 있으며, RIP는 경유하는 라우터의 대수(hop의 수량)에 따라 최단 경로를 동적으로 결정하는 거리 벡터(distance Vector) 알고리즘을 사용한다. ( ③ ) 은 링크 상태(Link-State) 라우팅 프로토콜로 IP 패킷에서 프로토콜 번호 89번을 사용하여 라우팅 정보를 전송하여 안정되고 다양한 기능으로 가장 많이 사용되는 ( ① )이다. 타 자치 시스템과의 라우팅 정보 교환을 위해서는 외부 라우팅 프로토콜인 ( ② )를 사용한다. 연구기관이나 국가기관, 대학, 기업 간, 즉 도메인(게이트웨이) 간에 라우팅 정보를 교환한다. ( ② )의 대표적인 프로토콜인 ( ④ )는 자치 시스템간의 라우팅 테이블을 전달하는데 주로 이용이 되며, 초기에 연결될 때에는 전체 경로 테이블의 내용을 교환하고, 이후에는 변화된 정보만을 교환한다. |
① IGP , ② EGP , ③ OSPF , ④ BGP
17. 다음 공통으로 설명하는 라우팅 프로토콜 명칭을 영문 약어로 쓰시오.
| - 패킷을 목적지까지 전달하기 위해 사용되는 라우팅 프로토콜이다. - 거리 벡터 기반 라우팅 프로토콜로 홉 수를 기반으로 경로를 선택한다. - 최대 15홉 이하 규모의 네트워크를 주요 대상으로 하는 라우팅 프로토콜이다. - 최적의 경로를 산출하기 위한 정보로서 홉(거리 값)만을 고려하므로, 선택한 경로가 최적의 경로가 아닌 경우가 많이 발생할 수 있다. |
RIP
11. 라우팅 프로토콜의 종류
- EGP (Exteior Gateway Protocol, 외부 게이트웨이 프로토콜)
- 연구기관이나 국가기관, 대학, 기업 간, 즉 도메인(게이트웨이) 간에 라우팅 정보를 교환한다.
- BGP (Border Gateway Protocol)
- 외부 라우팅 프로토콜로서 AS(Autonomous System) 간의 라우팅을 한다.
- 테이블을 전달하는 데 주로 이용한다.
- IGP (Interior Gateway Protocol, 내부 게이트웨이 프로토콜)
- 동일 그룹 내에서 라우팅 정보를 교환한다.
- RIP (Routing Information Protocol)
- 최단 경로 탐색에 Bellman-Ford 알고리즘을 사용하는 거리 벡터 라우팅 프로토콜이다.
- 최적의 경로를 산출하기 위한 정보로서 홉(거릿 값)만을 고려하므로, RIP를 선택한 경로가 최적의 경로가 아닌 경우가 많이 발생할 수 있다.
- 최대 홉 카운트를 15홉 이하로 한정한다.
- 소규모 네트워크 환경에 적합하다.
- OSPF (Open Shortest Path First Protocol)
- 링크 상태 라우팅 프로토콜로 IP 패킷에서 프로토콜 번호 89번을 사용하여 라우팅 정보를 전송하여 안정되고 다양한 기능으로 가장 많이 사용되는 IGP(Interior Gateway Protocol, 내부 라우팅 프로토콜)이다.
- OSPF 라우터는 자신의 경로 테이블에 대한 정보를 LSA라는 자료구조를 통하여 주기적으로 혹은 라우터의 상태가 변화되었을 때 전송한다.
- 라우터 간에 변경된 최소한의 부분만을 교환하므로 망의 효율을 저하시키지 않는다.
- 도메인 내의 라우팅 프로토콜로서 RIP가 가지고 있는 여러 단점을 해결하고 있다. RIP(Routing Information Protocol)의 경우 홉 카운트가 15로 제한되어 있지만 OSPF는 이런 제한이 없다.
| IGP (Interior Gateway Protocol) |
- AS(Autonomous System) 내부 라우터 간 - RIP, OSPF, IGRP |
| EGP (Exterior Gateway Protocol) |
- AS(Autonomous System) 외부 라우터 상호간 - EGP, BGP |

'정보처리기사' 카테고리의 다른 글
| [정보처리기사 요약정리] PART 5. 정보시스템 구축관리+ 기출포함 (26) | 2024.10.19 |
|---|---|
| [정보처리기사 요약정리] PART 3. 데이터베이스 구축 + 기출포함 (5) | 2024.10.19 |
| [정보처리기사 요약정리] PART 2. 소프트웨어 개발 + 기출포함 (11) | 2024.10.19 |
| [정보처리기사 요약정리] PART 1. 소프트웨어 설계 + 기출포함 (12) | 2024.10.18 |
| [정보처리기사 실기 기출] 2024년 2회 (14) | 2024.10.17 |