01. 다음 중 형상관리 도구에 해당하는 것을 모두 고르시오.
|
Ant, CVS, OLAP, Maven, SVN, Jenkins, OLTP, Git, Graddle
|
CVS, SVN, Git
* 형상 관리 절차
- 형상 식별 → 형상 통제 → 형상 감사 → 형상 기록
- 형상 통제 : 소프트웨어 형상 변경 요청을 검토하고 승인하여 현재의 베이스라인에 반영될 수 있도록 통제
* 형상관리 도구(버전관리 도구)
| CVS (Concurrent Versions System) |
- 오픈 소스 프로젝트에서 널리 사용되는 버전관리 시스템이다. - 소프트웨어 프로젝트를 진행할 때 파일로 이루어진 모든 작업과 모든 변화를 추적하고, 여러 개발자가 협력하여 작업할 수 있게 지원한다. - 최근에는 CVS가 한계를 맞아 이를 대체하는 SVN이 개발되었다. |
| Git | - 프로그램 등의 소스 코드 관리를 위한 분산 버전관리 시스템이다. - Linux 초기 커널 개발자인 리누스 토르발스가 리눅스 커널 개발에 이용하기 위해 개발하였으며, 현재는 다른 곳에도 널리 사용되고 있다. - 지역 저장소와 원격 저장소가 존재하며 지역 저장소에서 버전관리가 진행되어 버전관리가 빠르다. |
| SVN (Subversion) |
- CVS보다 속도 개선, 저장 공간, 변경 관리 단위가 작업 모음 단위로 개선되었고, 2000년 콜랩넷에서 개발되었다. - CVS와 사용 방법이 유사해 CVS 사용자가 쉽게 도입 가능하며 아파치 최상위 프로젝트로서 전 세계 개발자 커뮤니티와 함께 개발되어 있다. - 디렉터리, 파일을 자유롭게 이동해도 버전관리가 가능하다. |
02. 다음은 디자인 패턴에 대한 설명이다. 괄호안에 알맞은 답을 작성하시오.
|
- ( ① )은 구현부에서 추상층을 분리하여 각자 독립적으로 변형이 가능하고 확장이 가능하도록 합니다. 즉 기능과 구현에 대해서 두 개를 별도의 클래스로 구현을 합니다.
- ( ② ) 한 객체의 상태가 바뀌면 그 객체에 의존하는 다른 객체들한테 연락이 가고, 자동으로 내용이 갱신되는 방식의 패턴이다. |
① Bridge , ② Observer
03. 다음은 UML에 관한 설명이다. 괄호안에 알맞은 답을 작성하시오.
|
UML은 컴퓨터 애플리케이션을 모델링 할 수 있는 통합 언어이다. 구성요소로는 사물, ( ① ), 다이어그램으로 이루어져 있고, 구조 다이어그램 중 ( ② ) 다이어그램은, 객체들의 타입을 정의하고, 객체들간의 관계를 도식화하여 시스템의 특정 모듈이나 일부 및 전체를 구조화한다.
UML 모델링에서 ( ③ )는 클래스와 같은 기타 모델 요소 또는 컴포넌트가 구현해야 하는 오퍼레이션 세트를 정의하는 모델요소이다. |
① 관계 , ② 클래스 , ③ 인터페이스
* UML(Unified Modeling Language)
- 시나리오를 표현할 때 사례 다이어그램을 주로 사용한다.
- 구조 다이어그램(Structure Diagram)
- 시스템의 정적 구조(Static Structure)와 다양한 추상화 및 구현 수준에서 시스템의 구성요소, 구성요소 간의 관계를 보여 준다.
- 행위 다이어그램(Behavior Diagram)
- 시스템 내의 객체들의 동적인 행위(Dynamic Behavior)를 보여주며, 시간의 변화에 따른 시스템의 연속된 변경을 설명해준다.
* 관계
- 일반화 관계(Generalization) - 한 클래스가 다른 클래스를 포함하는 상위 개념일 때의 관계
- 연관관계(Association) - 한 클래스가 다른 클래스에서 제공하는 기능을 사용할 때 표시
- 의존관계(Dependency) - 클래스의 관계가 한 메서드를 실행하는 동안과 같이 매우 짧은 시간만 유지
- 실체화 관계(Realization) - 인터페이스를 구현받아 추상 메서드를 오버라이딩 하는 것을 의미
- 집약관계(Aggregation) - 전체 객체의 라이프타임과 부분 객체의 라이프타임은 독립적
- 합성관계(Composition) - 부분 객체가 전체 객체에 속하는 관계로 긴밀한 필수적 관계
* 유스케이스 다이어그램 관계
- 연관관계(Association) - 유스케이스와 액터 간의 상호작용이 있음을 표현
- 포함 관계(Include) - 유스케이스를 수행할 때 반드시 실행되어야 하는 경우
- 확장 관계(Extend) - 유스케이스를 수행 할 때 특정 조건에 따라 확장 기능 유스케이스를 수행하는 경우
04. 아래 점수에 따라 점수를 출력하는 테스트를 진행하려고 한다. 다음과 같은 테스트 입력 값을 넣을 때의 테스트 방식을 쓰시오.
| 점수 | 금액 | 테스트 입력 값 | |
| 90~100 | 700만원 | ① | |
| 80~89 | 500만원 | ② | |
| 70~79 | 300만원 | ③ | |
| 0~69 | 0만원 | ④ |
|
테스트 입력 값 : -1, 0, 1, 68, 69, 70, 99, 100, 101
|
Boundary Value Analysis (경곗값 분석)
* 블랙박스 테스트
- 동등 분할 기법(동치 분할 검사)
- 입력 자료에 초점을 맞춰 테스트 케이스를 만들어 검사하는 방법
- 입력 조건에 타당한 입력 자료와 그렇지 않은 자료의 개수를 균등하게 나눠 테스트 케이스를 설정한다.
- 경곗값 분석
- 입력 조건의 경계값을 테스트 케이스로 선정하는 방법
- 입력 자료에만 치중한 동치 분할 기법을 보완한 것
- 입력 조건 경계값에서 오류 발생 확률이 크다는 것을 활용하여 경계값 테스트 케이스로 선정해 검사한다.
- 원인-효과 그래프 검사
- 입력 데이터 간의 관계와 출력에 영향을 미치는 상황을 체계적으로 분석한 다음 효용성이 높은 테스트 케이스를 선정하여 검사하는 기법
- 오류 예측 검사
- 과거의 경험이나 테스터의 감각으로 테스트 하는 기법
- 다른 테스트 기법으로는 찾기 어려운 오류를 찾아내는 보충적 검사 기법이다.
- 비교 검사
- 여러 버전의 프로그램에 동일한 테스트 자료를 제공하여 동일한 결과가 출력되는지 테스트하는 기법
* 애플리케이션 테스트 유형 분류
- 프로그램 실행 여부
- 정적 테스트
- 동적 테스트
- 테스트 기법
- 화이트박스 테스트
- 블랙박스 테스트
- 테스트에 대한 시각
- 검증 테스트
- 확인 테스트
- 테스트 목적
- 회복 테스트
- 안전 테스트
- 강도 테스트
- 성능 테스트
- 구조 테스트
- 회귀 테스트
- 병행 테스트
- 테스트 기반
- 명세 기반 테스트
- 구조 기반 테스트
- 경험 기반 테스트
05. 아래에 설명하는 용어를 작성하시오.
|
- 여러 개의 사이트에서 한 번의 로그인으로 여러가지 다른 사이트들을 자동적으로 접속하여 이용하는 방법을 말한다.
- 하나의 시스템에서 인증을 할 경우 타 시스템에서는 인증 정보가 있는지 확인하고 있으면, 로그인 처리를 하도록 하고, 없는 경우, 다시 통합 인증을 할 수 있도록 만드는 것을 의미한다. |
SSO (Single Sign On)
* SSO(Single Sign On)
- '모든 인증을 하나의 시스템에서'라는 목적으로 개발된 인증 시스템이다.
- 한 번의 로그인으로 재인증 절차 없이 여러 개의 서비스들을 이용할 수 있게 해주는 시스템이다.
- 인증을 받은 사용자가 여러 정보 시스템에 재인증 절차 없이 반복해서 접근할 수 있도록 해주는 것이다.
06. 다음은 E-R 다이어그램에 대한 설명이다. 빈칸 ①~⑤의 설명에 각각 해당하는 기호를 골라쓰시오.
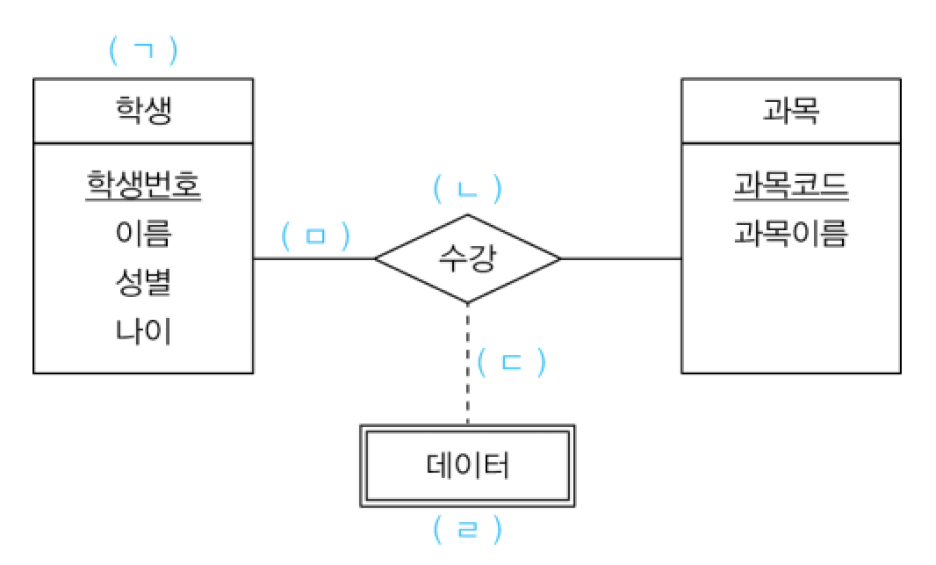
|
( ① ) : 관계 집합을 표시한다.
( ② ) : 외래키들을 기본키로 사용하지 않고 일반 속성으로 취급하는 비식별 관계를 연결한다. ( ③ ) : 개체 집합을 표시한다. 개체 집합의 속성으로 기본키를 명세할 수 있다. ( ④ ) : 자신의 개체 속성으로 기본키를 명세할 수 없는 개체 타입이다. ( ⑤ ) : 식별 관계로 개체 집합의 속성과 관계 집합을 연결한다. |
① ㄴ , ② ㄷ , ③ ㄱ , ④ ㄹ, ⑤ ㅁ
* ERD(Entity Relationship Diagram)

07. 다음은 프로세스 스케줄링에 관련된 내용이다. 괄호에 맞는 답을 작성하시오.
|
( ① ) : 선점형 스케줄링 기법으로 CPU 점유 시간이 가장 짧은 프로세스에 CPU를 먼저 할당하는 방식
( ② ) : 시간단위(Time Quantum/Slice)를 정해서 프로세스를 순서대로 CPU를 할당하는 방식 ( ③ ) : 비 선점형 스케줄링 기법으로 실행시간이 가장 짧은 프로세스에게 CPU를 할당하는 방식 |
① SRT (Shortest Remaining Time) , ② Round Robin , ③ SJF (Shorteset Job First)
* 프로세스 스케줄링(= CPU 스케줄링)
- 프로세스의 생성 및 실행에 필요한 시스템의 자원을 해당 프로세스에 할당하는 작업을 말한다.
| 비선점 (Non-preemptive) 스케줄링 |
- 일단 CPU를 할당받으면 다른 프로세스가 CPU를 강제적으로 빼앗을 수 없는 방식이다. - 모든 프로세스에 대한 공정한 처리가 가능하다. - 일괄 처리 시스템에 적합하다. - 비선첨 프로세스 : FCFS, SJF, HRN, 기한부, 우선순위 |
| 선점 (Preemptive) 스케줄링 |
- 한 프로세스가 CPU를 할당받아 실행 중이라도 우선순위가 높은 다른 프로세스가 CPU를 강제적으로 빼앗을 수 있는 방식이다. - 긴급하고 높은 우선순위의 프로세스들이 빠르게 처리될 수 있다. - 대화식 시분할 시스템에 적합하다. - 선점 프로세스 : SRT, RR, MQ, MFQ |
* 프로세스 스케줄링
- 프로세스의 생성 및 실행에 필요한 시스템의 자원을 해당 프로세스에 할당하는 작업을 말한다.
- 스케줄링의 기법은 비선점 기법과 선점 기법으로 구분할 수 있다.
* 비선점(Non-preemptive) 스케줄링
- 일단 CPU를 할당받으면 다른 프로세스가 CPU를 강제적으로 빼앗을 수 없는 방식
- 모든 프로세스에 대한 공정한 처리가 가능하다.
- 일괄 처리 시스템에 적합하다.
| FCFS (First Come First Service) |
준비상태 큐에 도착한 순서대로 CPU를 할당하는 기법 - 평균 대기시간, 최대/최소 평균 반환시간 |
| SJF (Shortest Job First) |
- 준비상태 큐에서 대기하는 프로세스들 중에서 실행 시간이 가장 짧은 프로세스에게 먼저 CPU를 할당하는 기법 - 평균 대기 시간을 최소화함 - 평균 실행시간, 평균 대기시간, 평균 반환시간 |
| HRN (Highest Response-ratio Next) |
- 어떤 작업이 서비스 받을 시간과 그 작업이 서비스를 기다린 시간으로 결정되는 우선순위에 따라 CPU를 할당하는 기법 - 우선순위 계산식 = ( 대기시간 + 서비스시간 ) / 서비스시간 |
| 기한부 (Deadline) |
작업이 주어진 특별한 시간이나 만료시간 안에 완료되도록 하는 기법 |
| 우선순위 (Priority) |
- 준비상태 큐에서 대기하는 프로세스에게 부여된 우선순위가 가장 높은 프로세스에게 먼저 CPU를 할다하는기법 - 에이징(Aging) 기법 : 프로세스가 자원을 기다리고 있는 시간에 비례하여 우선순위를 부여함으로써 무기한 문제를 방지하는 기법 |
* 선점(Preemptive) 스케줄링
- 한 프로세스가 CPU를 할당받아 실행 중이라도 우선순위가 높은 다른 프로세스가 CPU를 강제적으로 빼앗을 수 있는 방식
- 긴급하고 높은 우선순위의 프로세스들이 빠르게 처리될 수 있다.
- 대화식 시분할 시스템에 적합하다.
| SRT (Shortest Remaining Time) |
- 실행 중인 프로세스의 남은 시간과 준비상태 큐에 새로 도착한 프로세스의 실행 시간을 비교하여 실행 시간이 더 짧은 프로세스에게 CPU를 할당하는 기법 - 시분할 시스템에 유용함 - 평균 반환시간(최종 완료 시간 - 도착 시간) 그림그리기! |
| RR (Round Robin) |
- 주어진 시간 할당량 안에 작업을 마치지 않으면 준비완료 리스트의 가장 뒤로 배치되는 기법 - 시간 할당량이 너무 커지면 FCFS와 비슷하고, 시간 할당량이 너무 작아지면 오버헤드가 커지게 됨 - 사용 순서, 평균 대기시간, 평균 반환시간(대기시간을 먼저 구한 후, 대기시간+실행시간/개수) |
| 다단계 큐 (MQ, Multi-level Queue) |
프로세스들을 우선순위에 따라 시스템 프로세스, 대화형 프로세스, 일괄처리 프로세스 등으로 상위, 중위, 하위 단계의 단계별 준비 큐를 배치하는 방법 |
| 다단계 피드백 큐 (MFQ, Multi-lever Feedback Queue) |
- 각 준비상태 큐마다 부여된 시간 할당량 안에 완료하지 못한 프로세스는 다음 단계의 준비상태 큐로 이동하는 기법 - 짧은 작업, 입/출력 위주의 작업 권에 우선권을 부여함 - 마지막 단계의 큐에서는 작업이 완료될 때까지 RR 방식을 취함 |
08. 192.168.1.0./24 네트워크를 FLSM 방식으로 3개의 서브넷으로 나눴을 때, 두번째 네트워크의 브로드캐스트 아이피를 쓰시오.
192.168.1.127
- 서브넷팅(Subnetting) : IP 주소의 낭비를 막기 위해 네트워크를 여러 개의 서브넷으로 분리하는 과정이다.
- 서브넷(Subnet) : IP 주소에서 네트워크 영역을 부분으로 나눈 부분 네트워크이다.
- 서브넷 마스크(Subnet Mask) : IP 주소에서 Network ID와 Host ID를 분리하는 역할을 한다.
- FLSM(Fixed Length Subnet Mask, 고정길이 서브넷 마스크) 방식에서의 ip subnet-zero는 subnetting 후, 첫 번째 네트워크에 포함되는 IP Address를 사용할 수 있게 하여 주소 손실을 막는다.
- 3개의 서브넷으로 나누기 위해서는 2bit의 서브넷 마스크가 추가로 필요하다.
- 서브넷 마스크 : 255.255.255.192 /26
- 각 서브넷 당 호스트 수 : 2^(8-2) = 64개
- 2번째 서브넷 네트워크 IP 주소 : 192.168.1.64
- 2번째 서브넷 브로드캐스트 IP 주소 : 192.168.1.127
- 2번째 서브넷 IP 주소 범위 : 192.168.1.64 ~ 192.168.1.127
09. 아래 설명에 대한 알맞은 답을 작성하시오.
|
( ① ) : 기술적인 방법이 아닌 사람들 간의 기본적인 신뢰를 기반으로 사람을 속여 비밀정보를 획득하는 기법
( ② ) : 기업이 정보를 수집한 후, 저장만 하고 분석에 활용하고 있지 않은 다량의 데이터 |
① 사회공학 , ② 다크 데이터
| 사회 공학 (Social Engineering) |
- 정보보안에서 사람의 심리적인 취약점을 악용하여 비밀 정보를 취득하거나 컴퓨터 접근 권한 등을 얻으려고 하는 공격 방법이다. - 인간 기반 사회 공학 기법 : 휴지통 뒤지기, 출입문에서 앞사람 따라 들어가기, 어깨너머 훔쳐보기 등 - 컴퓨터 기반 사회 공학 기법 : 피싱(Pishing), 파밍(Pharming), 스미싱(Smishing) 등 |
| 다크 데이터 (Dark Data) |
'알 수 없는 데이터' 라고도 하며, 다양한 컴퓨터 네트워크를 통해 수집된 자료이나 분석이나 결과 도출을 위해 사용되지 않는 데이터를 의미한다. |
10. 아래 설명에 대한 알맞은 답을 작성하시오.
|
- 네트워크 하드웨어 및 응용 프로그램에 의해 생성된 보안 경고의 실시간 분석을 제공한다.
- 빅데이터 수준의 데이터를 장시간 심층 분석한 인덱싱 기반이다. - 주요 기능은 데이터 통합, 상관관계, 알림, 대시보드 |
SIEM (Security Information & Event Management)
* SIEM(Security Information Event Management)
- SIM(Security Information Management) + SEM(Security Event Management)
- 최근 빅데이터 분석 및 인공지능 기술의 발전으로 정보보안 분야에 적극적으로 활용되는 시스템이다.
| SIM | 분석을 위해 이벤트 및 활동 로그 데이터를 수집, 저장 및 모니터링하는 프로세스 |
| SEM | 64위협을 처리하고 패턴을 식별하여 위협에 대응하기 위해 보안 이벤트 및 경고를 실시간으로 모니터링 및 분석하는 프로세스 |
* 보안 솔루션
- 방화벽(Firewall) - 네트워크 간에 전송되는 정보를 선별하는 기능을 가진 침입 차단 시스템
- 웹방화벽(Web Firewall) - 웹 기반 공격을 방어할 목적으로 만들어진 웹서버 특화 방화벽
- 침입탐지 시스템(IDS; Intrucsion Detection System)
- 컴퓨터 시스템의 비정상적인 사용, 오용 등을 실시간으로 탐지하는 시스템
- 이상탐지, 오용탐지
- 침입방지 시스템(IPS; Intrusion Prevention System) - 방화벽과 침입탐지 시스템을 결합한 것.
- 데이터유출방지(DLP; Pata Leakage/Loss Privention) - 내부 정보의 유출을 방지하기 위한 보안솔류션
- NAC(Network Access Control) - 네트워크에 접속하는 내부 PC의 MAC주소를 IP관리시스템에 등록한 후 일관된 보안관리 기능을 제공하는 보안 솔루션
- ESM(Enterprise Security Management) - 다양한 장비에서 발생하는 로그 및 보안 이벤트를 통합관리하는 보안 솔루션
- SIEM(Security Information&Event Management) - 빅데이터 수준의 데이터를 장시간 심층 분석한 인덱싱 기반
- SOAR(Security Orchestration, Automation and Response) - 보안 오케스트레이션, 자동화 및 대응을 통해 IT 시스템을 보호하는 솔루션
- Sandbox - 응용 프로그램이 가상 환경에서 독립적으로 실행되는 형태
- FDS(Fraud Detection System) - 전자금융거래의 이상 거래를 탐지하고 차단하는 시스템
- Proxy Server - 클라이언트를 대신하여 인터넷상의 다른 서버에 접속하며, 방화벽 및 캐시 기능을 수행
11. 아래 설명에 대한 알맞은 답을 작성하시오.
|
( ① ) : 독립적인 보안 구역을 따로 두어 중요한 정보를 보호하는 하드웨어 기반의 보안 기술
( ② ) : 사용자가 사이트의 URL 주소를 입력할 때 철자를 잘못 입력하거나 빠뜨리는 실수를 이용하여, 해커가 만들어 놓은 유사한 URL로 접속하도록 유도하는 공격 |
① Trust Zone , ② 타이포스쿼팅 (Typosquatting)
| Trust Zone (트러스트 존) |
- 스마트콘의 QP칩(Application Processor, CPU칩)에 적용된 보안 영역이다. - AP칩 안에 안드로이드 OS와는 분리된 안전영역에 별도의 보안 OS(Secure OS)를 구동시키는 기술이다. |
| Typosquatting (타이포스쿼팅) |
- '가짜 URL', 'URL 하이재킹', '스팅 사이트'라고도 한다. - 웹 사용자의 주소 오타 입력을 기대하며 유사 사이트를 만들어 놓는 공격 기법으로, 사용자의 계정정보를 탈취하기 위한 피싱 사이트 운영, 악성코드 배포, 오픈소스 패키지를 사칭한 공급망 공격의 한 형태이다. |
12. 다음 항목에 맞는 관계대수 기호를 작성하시오.
| 항목 | 기호 |
| 합집합 | A ( ∪ ) B |
| 차집합 | A ( - ) B |
| 카티션 프로덕트 | A ( × ) B |
| 프로젝트 | A ( π ) B |
| 조인 | A ( ⋈ ) B |
* 관계 대수(Relational Algebra) : 원하는 정보와 그 정보를 어떻게 유도하는가를 기술하는 절차적인 방법
| 구분 | 연산자 | 기호 | 의미 |
| 순수 관계 연산자 |
Select | σ | 조건에 맞는 튜플을 구하는 수평적 연산 |
| Project | π | 속성 리스트로 주어진 속성만 구하는 수직적 연산 | |
| Join | ⋈ | 공통 속성을 기준으로 두 릴레이션을 합하여 새로운 릴레이션을 만드는 연산 | |
| Division | ÷ | 두 릴레이션 A, B에 대해 B 릴레이션의 모든 조건을 만족하는 튜플들을 릴레이션 A에서 분리해 내어 프로젝션하는 연산 | |
| 일반 집합 연산자 |
합집합 | ∪ | 두 릴레이션의 튜플의 합집합을 구하는 연산 |
| 교집합 | ∩ | 두 릴레이션의 튜플의 교집합을 구하는 연산 | |
| 차집합 | - | 두 릴레이션의 튜플의 차집합을 구하는 연산 | |
| 교차곱 | × | 두 릴레이션의 튜플들의 교차곱(순서쌍)을 구하는 연산 |
13. 아래의 테이블에서 SQL 명령을 수행할 경우 알맞은 값을 작성하시오.
<테이블 생성 SQL문>
create table 부서{
부서번호 char(2),
부서명 varchar(30),
primary key(부서번호)
);
create table 사원(
사원번호 int,
사원명 varchar(30),
부서번호 char(2),
primary key(사원번호),
foreign key(부서번호)
references 부서(부서코드) on delete cascade
);
<튜플 삽입 SQL문>
insert into 부서 (부서번호, 부서명) values('10', '관리부');
insert into 부서 (부서번호, 부서명) values('20', '기획부');
insert into 부서 (부서번호, 부서명) values('30', '영업부');
insert into 사원 (사원번호, 사원명, 부서번호) values (1000, '김사원', '10');
insert into 사원 (사원번호, 사원명, 부서번호) values (2000, '이사원', '20');
insert into 사원 (사원번호, 사원명, 부서번호) values (3000, '강사원', '20');
insert into 사원 (사원번호, 사원명, 부서번호) values (4000, '신사원', '20');
insert into 사원 (사원번호, 사원명, 부서번호) values (5000, '정사원', '30');
insert into 사원 (사원번호, 사원명, 부서번호) values (6000, '최사원', '30');
insert into 사원 (사원번호, 사원명, 부서번호) values (7000, '안사원', '30');① SELECT COUNT(DISTINCT 사원번호) FROM 사원 WHERE 부서번호 = '20';
② DELETE FROM 부서 WHERE 부서번호 = '20';
SELECT COUNT(DISTINCT 사원번호) FROM 사원;① 3, ② 4
- ① SELECT COUNT(DISTINCT 사원번호) FROM 사원 WHERE 부서번호 = '20';
- <사원> 테이블에서 부서번호가 '20'인 사원의 수를 출력하시오.
- ② DELETE FROM 부서 WHERE 부서번호 = '20';
SELECT COUNT(DISTINCT 사원번호) FROM 사원;- <부서> 테이블에서 부서번호가 '20'인 부서 정보를 삭제한 후, <사원> 테이블에 있는 사원의 수를 출력하시오.
14. STUDENT 테이블에 컴퓨터학과 학생 50명, 기계과 학생 100명, 건축과학생 50명의 데이터가 있다. 다음 SQL문의 실행결과 튜플의 수는 몇인지 작성하시오.
|
① SELECT DEPT FROM STUDENT;
② SELECT DISTINCT DEPT FROM STUDENT; ③ SELECT COUNT(DISTINCT DEPT) FROM STUDENT WHERE DEPT='건축과'; |
① 200 , ② 3 , ③ 1
- SELECT문의 DISTINCT 옵션은 테이블 내의 튜플(행) 중 동일한 튜플이 존재할 경우 한 튜플만 남기고 나머지 튜플들은 제거한다.
15. 다음 C언어 프로그램의 출력결과를 쓰시오.
#include<stdio.h>
int mark(int, int, int, int);
int main(){
int mines[4][4] = { {0,0,0,0}, {0,0,0,0}, {0,0,0,0}, {0,0,0,0} };
int field[4][4] = { {0,1,0,1}, {0,0,0,1}, {1,1,1,0}, {0,1,1,1} };
int w = 4;
int h = 4;
int y, x, i, j;
for (y=0; y<h; y++){
for (x=0; x<w; x++){
if(field[y][x] == 0) continue;
for (i=y-1; i<=y+1; i++){
for (j=x-1; j<=x+1; j++){
if (mark(w, h, j, i)==1) mines[i][j] += 1;
}
}
}
}
for(y=0; y<h; y++){
for(x=0; x<w; x++){
printf("%d ", mines[y][x]);
}
printf("\n");
}
return 0;
}
int mark(int w, int h, int j, int i) {
if(i>=0 && j<h && j>=0 && j<w) return 1;
return 0;
}1 1 3 2
3 4 5 3
3 5 6 4
3 5 5 3
- 해당 프로그램은 2차원 배열의 각 요소를 중심으로 본인 요소를 둘러싼 사각형 영역의 값들을 누적하여 출력하는 프로그램이다.
- 2차원 배열 field는 4행 4열 요소이다.
- mark() 함수를 통해 2차원 배열 field의 각 요소를 둘러싼 요소의 값을 누적하여 2차원 배열 mines의 동일 위치의 요소의 값으로 저장한다.
16. 다음 C언어 프로그램의 출력결과를 쓰시오.
int main(){
int rank[5];
int arr[] = {77, 32, 20, 99, 55};
for (int i=0; i<5; i++){
rank[i] = 1;
for (int j=0; i<5; j++)
if (arr[i] < arr[j]) rank[i]++;
}
for (int k=0; k<5; k++)
printf("%d", rank[k]);
}24513
- 해당 프로그램은 1차원 배열의 각 요소의 배열 내의 등수를 출력하는 프로그램이다. (가장 큰 값이 1등)
- 5개의 요소에 대해 각각 5번 비교를 통해(총 25회) 해당 요소가 배열 내의 등수(순위)를 구하는 방법은 모든 요소는 1등으로 초기화를 한 후, 본인보다 큰 값이 등장하면 등수를 1씩 증가시키는 알고리즘이 적용되어 있다.
17. 다음 C언어 프로그램의 출력결과를 쓰시오.
#include <stdio.h>
int main(){
int n, k, s, i;
int cnt = 0;
for (int n=6; n<=30; n++){
s = 0;
k = n/2;
for (int j=1; j <= y; j++){
if ( i % j == 0 )
x = x+j ;
}
if (x==i){
cnt++;
}
}
}
printf("%d", cnt);
return 0;
}2
- 해당 프로그램은 6~30 사이의 정수 중 완전수의 개수(6과 28)를 출력하는 프로그램이다.
- 완전수란, 자기 자신을 제외한 약수(진약수)를 모두 더했을 때 자기 자신이 되는 양의 정수(6, 28, 496, 8128, 33550336)이다.
- 예를 들어, 6의 약수는 1, 2, 3, 6이고 6을 제외한 1+2+3을 수행하면 6이므로 6은 완전수이다.
- k = n / 2; 명령문의 경우는 자기 자신을 제외한 정수 중 가장 큰 약수는 자기 자신을 2로 나눈 수보다 클 수 없으므로 2로 나눈 값 이후는 약수 판별을 하는 것이 의미가 없으므로 반복전 n의 값을 2로 나누어 준다.
- 예를 들어 n이 6인 경우, 2로 나눈 3 이후의 6의 약수는 존재하지 않으므로 1부터 3까지 사이에서 6의 약수를 판별하고 1, 2, 3의 합계를 구한 후, 6과 비교하는 것이 효율적이다.
- 6이상 30이하의 완전수는 6과 28이므로 완전수의 개수 cnt는 2이다.
18. 다음 JAVA 프로그램의 출력결과를 쓰시오.
public class Exam{
static int nSize = 4;
public static void makeArray(int[] arr){
for (int i=0; i<nSize; i++){
arr[i] = i;
}
}
public static void main(String[] args){
int[] arr = new int[nSize];
makeArray(arr);
for( int i=0; i<nSize; i++)
System.out.print(arr[i] + " ");
}
}
}0 1 2 3
- 해당 프로그램은 Java의 1차원 배열 객체를 생성(new)하고 각 요소에 값을 할당한 후 배열의 요소(값)을 출력하는 프로그램이다.
- main() 메소드 내에서 new int[4];를 가장 먼저 실행하여 클래스 필드 값 정수 4개의 요소를 갖는 1차원 배열 객체를 생성한다. 이후 이 객체는 참조변수 arr을 통해 접근한다.
- makeArray(arr); 명령문을 통해 호출한 makeArray() 메소드 내에서는 0~3회까지의 4회 반복을 통해 배열 객체의 요소에 값을 각각 할당한다.
- main() 메소드 내로 반환한 후, 반복문 for문 통해 1차원 배열 arr 객체의 0번째 요소부터 3번째 요소까지 요소의 값을 각각 출력한다.
19. 다음 JAVA 프로그램의 출력결과를 쓰시오.
int a = 0;
for (int i=1; i<999; i++){
if(i%3 == 0 && i%2 != 0)
a = i;
}
System.out.print(a);993
- 해당 프로그램은 1~998 사이 3의 배수이면서 홀수인 정수의 최댓값을 출력한다.
- 변수 a는 출력될 최대값을 저장하는 변수로 초기값은 0으로 설정하며, 반복문 내에서 if의 조건식이 만족하면 최대값을 갱신하여 저장하는 역할을 한다.
- if(i%3 == 0 && i%2 != 0) 조건문은 i가 3으로 나누어 떨어지면서 2로 나누어 떨어지지 않는 경우의 i 값에 참(true)로 판별한다.
- 즉, 998부터 역순으로 1씩 감소하며 3의 배수이면서 홀수인 정수를 찾아내면 가장 큰 정수(최대값)을 쉽게 찾을 수 있다.
20. 다음 파이썬 코드에 대한 출력값을 작성하시오.
arr = [1, 2, 3, 4, 5]
arr = list(map(lambda num : num+100, arr))
print(arr)[101, 102, 103, 104, 105]
- arr = [1, 2, 3, 4, 5] : 리스트 객체 arr을 생성한다.
- map(함수, 리스트객체) 함수 : 입력 개수만큼 함수를 여러 번 호출한다. → (결과)map 객체로 반환한다.
- 람다(lambda) 함수 : 필요할 때 바로 정의해서 사용하는 일시적인 함수이다.
- list() 함수 : 리스트 객체를 생성하는 함수이다.
- arr = list(map(lambda num : num+100, arr))
| 실행 | 순서 | 설명 |
| 1 | lambda num : num+100 | 매개변수 num에 100을 더해주는 람다 함수 |
| 2 | map(lambda num : num+100, arr) | map() 함수의 두 번째 객체의 요소를 차례대로 람다 함수에 대입하여 반복 호출 |
| map(람다 함수, [1, 2, 3, 4, 5]) | ||
| 3 | list(map(lambda num : num+100, arr)) | map 객체 반환된 결과를 list 객체로 변환 |
| 4 | arr = [101, 102, 103, 104, 105] | arr 객체에 결과 list 객체를 할당 |
해설은 유투브 흥달쌤 강의와, 이기적 실기 기본서를 참고하였습니다 :)
https://youtu.be/9DR7aSWPFfo?si=p0hKk384jfORFpA2
https://youtu.be/ss13H0iEeic?si=eUQncPcLurCnXJ1m

728x90
반응형
'정보처리기사' 카테고리의 다른 글
| [정보처리기사 실기 기출] 2023년 2회 (4) | 2024.10.16 |
|---|---|
| [정보처리기사 실기 기출] 2023년 1회 (6) | 2024.10.15 |
| [정보처리기사 실기 기출] 2022년 2회 (21) | 2024.10.13 |
| [정보처리기사 실기 기출] 2022년 1회 (17) | 2024.10.11 |
| [정보처리기사 실기 기출] 2021년 3회 (3) | 2024.10.11 |