1. 다음 Java 코드에서 알맞는 출력 값을 작성하시오.
class Connection {
private static Connection _inst = null;
private int count = 0;
static public Connection get() {
if(_inst == null) {
_inst = new Connection();
return _inst;
}
return _inst;
}
public void count() {
count++;
}
public int getCount() {
return count;
}
}
public class main {
public static void main(String[] args) {
Connection conn1 = Connection.get();
conn1.count();
Connection conn2 = Connection.get();
conn2.count();
Connection conn3 = Connection.get();
conn3.count();
conn1.count();
System.out.print(conn1.getCount());
}
}
4
* Java 언어, Connection()
- 해당 프로그램은 싱글톤 패턴(Singleton pattern)이 적용된 프로그램으로 프로그램이 실행되는 동안 클래스를 생성하는 객체(인스턴스)가 오직 하나이다.
- 싱글톤 패턴을 자바로 구현하는 3단계
- 생성자 메서드를 private로 접근 제한
- private static 인스턴스 변수 선언(오직 하나의 같은 오브젝트를 참조)
- public static Connection get() 메소드 구현
- 참조 변수 conn1, conn2, conn3는 같은 객체를 참조하며, 객체 내의 필드 count가 0으로 초기화 된 후, conn1.count(); 메소드 호출로 count가 1, conn2.count(); 메소드 호출로 count가 2, conn3.count(); 메소드 호출로 count가 3, conn1.count(); 메소드 호출로 count가 4가 되어 최종 출력 결과는 4이다.
2. 다음 C언어 코드에서 알맞는 출력 값을 작성하시오.
#include <stdio.h>
int main() {
int v1 = 0, v2 = 35, v3 = 29;
if(v1 > v2 ? v2 : v1) {
v2 = v2 << 2;
}else{
v3 = v3 << 2;
}
printf("%d", v2+v3);
}
151
* C언어, 시프트(shift) 연산
* 비트 시프트 연산자
| << | 비트를 왼쪽으로 이동(Shift)시킨다. |
| >> | 비트를 오른쪽으로 이동(Shift)시킨다. |
- if(v1 > v2 ? v2 : v1)
- 삼항연산자 : v1 > v2가 false이므로 삼항 연산자는 v1을 선택한다. 즉, if (v1)로 평가되며, v1의 값이 0이기 때문에, if 문 조건은 false로 else문으로 이동한다.
- v3 = v3 << 2;
- v3의 값인 29를 왼쪽으로 2번 시프트 연산한다.
- 29의 이진 표현은 00011101이며, 왼쪽으로 2번 시프트하면 01110100이 된다.
- 이 결과는 십진수로 116이므로, v3는 116이다.
- printf("%d", v2 + v3);
- v2 + v3 = 116 + 35 = 151 이다.
3. 응집도가 높은 순으로 나열하시오.
| ㄱ. 기능 ㄴ. 교환 ㄷ. 우연 ㄹ. 시간 |
ㄱ - ㄴ - ㄹ- ㄷ
* 응집도(Cohesion)
- 모듈 안의 요소들이 서로 기능적으로 관련되어 있는 정도
- 응집도가 강할수록 높은 품질의 모듈이다.
* 응집도 유형
| 기능적 (Functional) |
모듈 내부의 모든 기능 요소들이 한 문제와 연관되어 수행되는 경우 | 응집도 강함 |
| 순차적 (Sequential) |
한 모듈 내부의 한 기능요소에 의한 출력 자료가 다음 기능 요소의 입력 자료로 제공되는 경우 | |
| 통신(교환)적 (Communication) |
동일한 입력과 출력을 사용하는 소작업들이 모인경우 | |
| 절차적 (Procedural) |
모듈이 다수의 관련 기능을 가질 때 모듈 내부의 기능 요소들이 그 기능을 순차적으로 수행할 경우 | |
| 시간적 (Temporal) |
특정 시간에 처리되는 여러 기능을 모아 한 개의 모듈로 작성할 경우 | |
| 논리적 (Logical) |
유사한 성격을 갖거나 특정 형태로 분류되는 처리 요소들로 하나의 모듈이 형성되는 경우 | |
| 우연적 (Coincidental) |
모듈 내부의 각 기능 요소들이 서로 관련이 없는 요소로만 구성된 경우 | 응집도 약함 |
4. 다음은 C언어에 대한 문제이다. 알맞은 출력 값을 작성하시오.
#include <stdio.h>
#include <string.h>
void reverse(char* str){
int len = strlen(str);
char temp;
char* p1 = str;
char* p2 = str + len - 1;
while(p1<p2){
temp = *p1;
*p1 = *p2;
*p2 = temp;
p1++;
p2--;
}
}
int main(int argc, char* argv[]){
char str[100] = "ABCDEFGH";
reverse(str);
int len = strlen(str);
for(int i=1; i<len; i+=2){
printf("%c",str[i]);
}
return 0;
}
GECA
* C언어, reverse()
- 해당 프로그램은 주어진 str를 reserve(char* str) 메서드를 통해 뒤집은 후, for()문에 의해 1, 3, 5, 7번째 문자를 출력하는 프로그램이다.
5. 아래 그림에서의 네트워크에서 라우터를 통한 할당 가능한 2번, 4번, 5번의 IP를 작성하시오.

<보기>
| 192.168.35.0 192.168.35.72 192.168.36.0 192.168.36.249 129.200.8.0 129.200.8.249 |
(2) : 192.168.35.72
(4) : 129.200.8.249
(5) : 192.168.36.249
- 이 문제는 특정 네트워크 범위 내에서 사용 가능한 IP 주소를 찾고, 2번, 4번, 5번 위치에 지정하는 것을 묻는 문제이다.
- 주어진 정보는 각 네트워크의 범위를 정의하고 있으며, 문제에서 제공된 보기의 IP 주소를 참조하여 번호에 맞게 할당해야 한다.
* 각 네트워크와 서브넷의 범위 확인
- 네트워크 범위와 서브넷에 따라 할당할 수 있는 IP 주소는 다음과 같습니다.
- ① 192.168.35.3/24
- 서브넷 마스크: 255.255.255.0
- 네트워크 범위: 192.168.35.0 ~ 192.168.35.255
- 할당 가능한 보기 IP: ② 192.168.35.72 (해당 네트워크 범위 내에서 유일한 보기 IP)
- ③ 129.200.10.16/22
- 서브넷 마스크: 255.255.252.0
- 네트워크 범위: 129.200.8.0 ~ 129.200.11.255
- 할당 가능한 보기 IP: ④ 129.200.8.249 (해당 네트워크 범위 내에서 유일한 보기 IP)
- ⑥ 192.168.36.24/24
- 서브넷 마스크: 255.255.255.0
- 네트워크 범위: 192.168.36.0 ~ 192.168.36.255
- 할당 가능한 보기 IP: ⑤ 192.168.36.249 (해당 네트워크 범위 내에서 유일한 보기 IP)
6. 아래 표에서 나타나고 있는 정규형을 작성하시오.
| 고객아이디 | 강좌명 | 강사번호 |
| apple | 영어회화 | P001 |
| banana | 기초토익 | P002 |
| carrot | 영어회화 | P001 |
| carrot | 기초토익 | P004 |
| orange | 영어회화 | P003 |
| orange | 기초토익 | P004 |
제 3정규형
* 정규화 과정
비정규 릴레이션
⬇️
원자값이 아닌 도메인을 분해
1NF ⬇️
부분 함수 종속 제거
2NF ⬇️
이행 함수 종속 제거
3NF ⬇️
결정자나 후보키가 아닌 함수 종속 제거
BCNF ⬇️
다치 종속성 제거
4NF ⬇️
조인 종속
5NF ⬇️
- 이 테이블에서 고객아이디와 강좌명을 결합하면 고유한 레코드를 식별할 수 있으므로 (고객아이디, 강좌명)이 기본 키가 된다.
- 그러나 강좌명이 강사번호를 결정하고 있다. 이는 기본 키에 대한 종속 관계가 아니므로 강좌명 → 강사번호와 같은 비이행적 종속을 제거해야 제3정규형을 만족할 수 있다.
* 함수 종속성(Functional Dependency)
- 개체 내에 존재하는 속성 간의 관계를 종속적인 관계로 정리하는 방법이다.
- 데이터 속성들의 의미와 속성 간의 상호관계로부터 도출되는 제약조건이다.
| 부분 함수 종속 (Partial Functional Dependency) |
릴레이션에서 한 속성이 기본키가 아닌 다른 속성에 종속이 되거나 또는 기본키가 2개 이상 합성키로 구성된 경우 이 중 일부 속성에 종속이 되는 경우 |
| 완전 함수 종속 (Full Functional Dependency) |
릴레이션에서 한 속성이 오직 기본키에만 종속이 되는 경우 |
| 이행적 함수 종속 (Transitive Functional Dependency) |
릴레이션에서 A, B, C 세 속성 간의 종속이 A → B, B → C일 때, A → C가 성립이 되는 경우 |
7. 아래의 내용에서 설명하는 네트워크 용어를 영문 약어로 작성하시오.
| - 대표적인 링크 상태 라우팅 프로토콜이다. 이것은 인터넷에서 연결된 링크의 상태를 감시하여 최적의 경로를 선택한다는 것이다. - 단일 자율 시스템 내에서 라우팅 정보를 배포하는 데 사용되는 내부 게이트웨이 프로토콜이다. - 모든 대상에 도달하기 위한 최단 경로를 구축하고 계산하며 최단 경로는 Dijkstra 알고리즘을 사용하여 계산된다. |
OSPF
* OSPF(Open Shortest Path First)
- 링크 상태 라우팅 프로토콜로 IP 패킷에서 프로토콜 번호 89번을 사용하여 라우팅 정보를 전송하여 안정되고 다양한 기능으로 가장 많이 사용되는 IGP(Interior Gateway Protocol, 내부 라우팅 프로토콜)이다.
- OSPF 라우터는 자신의 경로 테이블에 대한 정보를 LSA라는 자료구조를 통하여 주기적으로 혹은 라우터의 상태가 변화되었을 때 전송한다.
- 라우터 간에 변경된 최소한의 부분만을 교환하므로 망의 효율을 저하시키지 않는다.
- 도메인 내의 라우팅 프로토콜로서 RIP가 가지고 있는 여러 단점을 해결하고 있다. RIP(Routing Information Protocol)의 경우 홉 카운트가 15로 제한되어 있지만 OSPF는 이런 제한이 없다.
* 라우팅 영역에 따른 분류
| IGP (Interior Gateway Protocol) |
- AS(Autonomous System) 내부 라우터 간 - RIP, OSPF, IGRP |
| EGP (Exterior Gateway Protocol) |
- AS(Autonomous System) 외부 라우터 상호간 - EGP, BGP |
8. 아래 내용의 각각의 설명에 대한 답을 작성하시오.
| (1) 조인에 참여하는 두 릴레이션의 속성 값을 비교하여 조건을 만족하는 튜플만 반환한다. (2) 조건이 정확하게 '=' 등호로 일치하는 결과를 반환한다. (3) (2) 조인에서 조인에 참여한 속성이 두 번 나오지 않도록 중복된 속성을 제거한 결과를 반환한다. |
(1) : 세타 조인
(2) : 동등 조인
(3) : 자연 조인
* 조인(JOIN)
- 둘 이상의 테이블로부터 특정 공통된 값을 갖는 행을 연결하거나 조합하여 검색하는 것으로 관계형 DBMS에서 매우 중요한 연산이다.
| 세타 조인 (Theta Join) |
- 조인에 참여하는 두 릴레이션의 속성 값을 비교하여 조건을 만족하는 튜플만 반환한다. - 비교 연산자로 =, >, <, >=, <=, <> 등이 사용될 수 있다. - 일반적으로 모든 조건 기반 조인을 세타 조인이라고 부르며, 동등 조인과 자연 조인 또한 세타 조인의 특수한 경우로 볼 수 있으며, 두 테이블 간의 특정 관계를 규명할 때 사용된다. |
| 동등 조인 (Equi Join) |
- 조건이 정확하게 '=' 등호로 일치하는 결과를 반환한다. - 조인 대상이 되는 두 테이블에서 공통적으로 존재하는 컬럼의 값이 일치되는 공통 행을 연결하여 결과를 생성하는 조인 방법 - 동등 조인은 WHERE절에 조인 조건으로 '=' 비교 연산자를 사용한다. |
| 자연 조인 (Natural Join) |
- 동등 조인에서 조인에 참여한 속성이 두 번 나오지 않도록 중복된 속성을 제거한 결과를 반환한다. - 테이블 간의 모든 컬럼을 대상으로 공통 컬럼을 자동으로 조사하여 같은 컬럼명을 가진 값이 일치할 경우 조인 조건을 수행한다. |
9. 다음의 운영체제 페이지 순서를 참고하여 할당된 프레임의 수가 3개일 때 LFU와 LFU 알고리즘의 페이지 부재 횟수를 작성하시오.
| 페이지 참조 순서 : 1, 2, 3, 1, 2, 4, 1, 2, 5, 7 |
(1) LRU : 6
(2) LFU : 6
* 페이지 교체 알고리즘
- 프로세스 실행 시 페이지 부재(Page Fault) 발생 시 가상기억장치의 페이지를 주기억장치에 적재해야 하는데, 이때 주기억장치의 모든 페이지 프레임이 사용 중이면 어떤 페이지 프레임을 교체할 지 결정하는 기법이다.
- 교체 알고리즘의 종류
| OPT (OTPimal page relpacement) |
- 이후에 가장 오랫동안 사용되지 않을 페이지를 먼저 교체하는 기법 - 실현 가능성이 희박함 |
| FIFO (First In First Out) |
- 가장 먼저 적재된 페이지를 먼저 교체하는 기법 - 벨레이디의 모순(Belady's Anomaly) 현상이 발생함 |
| LRU (Least Recently Used) |
가장 오랫동안 사용되지 않았던 페이지를 먼저 교체하는 기법 |
| LFU (Least Requently Used) |
참조된 횟수가 가장 적은 페이지를 먼저 교체하는 기법 |
| NUR (Not Used Recently) |
- 최근에 사용하지 않은 페이지를 먼저 교체하는 기법 - 매 페이지마다 두 개의 하드웨어 비트(참조 비트, 변형 비트)가 필요함 |
| SCR (Second Chance Replacement) |
각 페이지에 프레임을 FIFO 순으로 유지하면서 LRU 근사 알고리즘처럼 참조 비트를 갖게 하는 기법 |
* 페이지 부재(Page Fault)
- 참고할 페이지가 주기억장치에 없는 현상이다.
- 페이지 부재율(Page Fault Rate)에 따라 주기억장치에 있는 페이지 프레임의 수를 늘리거나 줄여 페이지 부재율을 적정 수준으로 유지하는 것이 바람직하다.
* LRU (Least Recently Used) 알고리즘
- LRU는 가장 오랫동안 사용되지 않은 페이지를 교체하는 방식
- 각 페이지가 참조될 때, 페이지가 가장 최근에 참조된 순서를 기준으로 교체 대상이 결정
- LRU 알고리즘 수행 과정
| 단계 | 참조 페이지 | 프레임 상태 | 페이지 부재 | 교체된 페이지 |
| 1 | 1 | [1] | O | - |
| 2 | 2 | [1, 2] | O | - |
| 3 | 3 | [1, 2, 3] | O | - |
| 4 | 1 | [1, 2, 3] | X | - |
| 5 | 2 | [1, 2, 3] | X | - |
| 6 | 4 | [1, 2, 4] | O | 3 |
| 7 | 1 | [1, 2, 4] | X | - |
| 8 | 2 | [1, 2, 4] | X | - |
| 9 | 5 | [1, 2, 5] | O | 4 |
| 10 | 7 | [7, 2, 5] | O | 1 |
- 총 페이지 부재 횟수 (LRU): 6회
* LFU (Least Frequently Used) 알고리즘
- LFU는 참조 횟수가 가장 적은 페이지를 교체
- 동일한 참조 횟수를 가진 페이지가 여러 개 있을 경우, 가장 오래된 페이지를 교체 대상으로 선택
- LFU 알고리즘 수행 과정
| 단계 | 참조 페이지 | 프레임 상태 | 페이지 부재 | 교체된 페이지 | 각 페이지 빈도 (참고) |
| 1 | 1 | [1] | O | - | 1(1) |
| 2 | 2 | [1, 2] | O | - | 1(1), 2(1) |
| 3 | 3 | [1, 2, 3] | O | - | 1(1), 2(1), 3(1) |
| 4 | 1 | [1, 2, 3] | X | - | 1(2), 2(1), 3(1) |
| 5 | 2 | [1, 2, 3] | X | - | 1(2), 2(2), 3(1) |
| 6 | 4 | [1, 2, 4] | O | 3 | 1(2), 2(2), 4(1) |
| 7 | 1 | [1, 2, 4] | X | - | 1(3), 2(2), 4(1) |
| 8 | 2 | [1, 2, 4] | X | - | 1(3), 2(3), 4(1) |
| 9 | 5 | [1, 2, 5] | O | 4 | 1(3), 2(3), 5(1) |
| 10 | 7 | [1, 2, 7] | O | 5 | 1(3), 2(3), 7(1) |
- 총 페이지 부재 횟수 (LFU): 6회
10. 다음 Java언어 코드의 실행 순서를 중복 번호 없이 작성하시오.
class Parent {
int x, y;
Parent(int x, int y) { // ①
this.x=x;
this y=y;
}
int getT() { // ②
return x*y;
}
}
class Child extend Parent {
int x;
Child (int x) { // ③
super(x+1, x);
this.x=x;
}
int getT(int n){ // ④
return super.getT()+n;
}
}
class Main {
public static void main(String[] args) { // ⑤
Parent parent = new Child(3); // ⑥
System.out.println(parent.getT()); // ⑦
}
}
| 실행 순서 : 5 - ( ) - ( ) - ( ) - ( ) - ( ) |
6 - 3 - 1 - 7 - 2
* Java언어, 상속 실행 순서
- ⑤ public static void main(String[] args) { :
- main 메서드가 시작된다. 이 메서드는 Java 프로그램의 진입점으로, 여기서부터 실행이 시작된다.
- Parent parent = new Child(3);를 통해 Child 클래스의 객체를 생성한다. 이때 Child 클래스의 생성자가 호출된다.
- ⑥ Parent parent = new Child(3);
- Child(int x) 생성자가 호출되며, 인자로 3이 전달된다.
- ③ Child (int x) { :
- Child 클래스의 생성자에서 super(x + 1, x);가 호출되어 Parent 클래스의 생성자가 실행된다. 즉, super(4, 3);가 된다.
- ① Parent(int x, int y) { :
- Parent(int x, int y) 생성자가 호출된다. 이때 x는 4, y는 3으로 초기화된다.
- this.x = x;와 this.y = y;를 통해 Parent 클래스의 인스턴스 변수가 설정된다.
- ⑦ System.out.println(parent.getT());
- System.out.println(parent.getT());에서 parent.getT()가 호출된다.
- parent는 Child 객체를 참조하고 있으므로 Parent 클래스의 getT() 메서드가 호출된다.
- ② int getT() { :
- getT() 메서드는 return x * y;를 수행한다. 이때 x는 4이고 y는 3이므로 결과는 4 * 3 = 12이다.
- getT() 메서드의 결과가 System.out.println을 통해 출력된다. 최종적으로 12가 출력된다.
11. 다음 C언어의 알맞은 출력 값을 작성하시오.
#include <stdio.h>
typedef struct{
int accNum;
double bal;
}BankAcc;
double sim_pow(double base, int year){
int i;
double r = 1.0;
for(i=0; i<year; i++){
r = r*base;
}
return r;
}
void initAcc(BankAcc *acc, int x, double y){
acc -> accNum = x;
acc -> bal = y;
}
void xxx(BankAcc *acc, double *en){
if (*en > 0 && *en < acc -> bal) {
acc -> bal = acc -> bal-*en;
}else{
acc -> bal = acc -> bal+*en;
}
}
void yyy(BankAcc *acc){
acc -> bal = acc -> bal * sim_pow((1+0.1),3);
}
int main(){
BankAcc myAcc;
initAcc(&myAcc, 9981, 2200.0);
double amount = 100.0;
xxx(&myAcc, &amount);
yyy(&myAcc);
printf("%d and %.2f", myAcc.accNum, myAcc.bal);
return 0;
}
9981 and 2795.10
* C언어, 이자 계산
- BankAcc myAcc;
- 위 코드에 의해 struct가 선언된다.
- initAcc(&myAcc, 9981, 2200.0);
- BankAcc의 accNum에는 9981, bal에는 2200.0이 할당된다.
- xxx(&myAcc, &amount);
- BankAcc과, amount=100.0 이다. 이때 BankAcc의 acc -> bal은 2200.0 이고, *en은 100.0 이므로 if문을 실행한다.
- acc -> bal은 2100.0(2200.0 - 100.0)이 된다.
- yyy(&myAcc);
- acc -> bal은 2100.0*sim_pow(1.1, 3) 을 통해 2795.10(2100.0 * 1.331) 이 된다.
- sim_pow(1.1, 3); 을 실행하면 다음과 같다.
- i=0; r = 1 * 1.1 = 1.1
- i=1; r = 1.1 * 1.1 = 1.21
- i=2; r = 1.21 * 1.1 = 1.331
- acc -> bal은 2100.0*sim_pow(1.1, 3) 을 통해 2795.10(2100.0 * 1.331) 이 된다.
- printf("%d and %.2f", myAcc.accNum, myAcc.bal);
- 9981 and 2795.10
12. 다음 Python 코드에 대한 알맞은 출력 값을 작성하시오.
a = ["Seoul", "Kyeonggi", "Incheon", "Daejun", "Daegu", "Pusan"]
str = "S"
for i in a:
str = str + i[1]
print(str)
Seynaau
* Python언어, 문자열 리스트
- 해당 프로그램은 문자열 리스트에서 각 도시 이름의 두 번째 문자를 추출하여 새로운 문자열을 구성하는 프로그램이다.
- 결과적으로 "Seynaau"가 출력되며, 이는 리스트의 모든 요소를 순회하면서 두 번째 문자를 조합한 결과이다.
13. 아래 보기의 SQL 문장과 테이블을 참고하여 출력 값을 표로 작성하시오.
SELECT B FROM R1
WHERE C IN (SELECT C FROM R2 WHERE D="k");
<R1>
| A | B | C |
| 1 | a | x |
| 2 | b | x |
| 1 | c | w |
| 3 | d | w |
<R2>
| C | D | E |
| x | k | 3 |
| y | k | 3 |
| z | s | 2 |
<답>
| B |
| a |
| b |
- 이 SQL 쿼리는 R2 테이블에서 특정 조건을 만족하는 C 값을 찾고, 이를 바탕으로 R1 테이블에서 관련된 B 값을 추출하는 과정을 보여준다.
- SELECT C FROM R2 WHERE D="k";
- 이 서브쿼리는 R2 테이블에서 열 C를 선택한다. 단, D가 "k"인 조건을 만족하는 행만 포함된다.
- R2 테이블에서 D가 "k"인 행을 찾으면:
- 첫 번째 행: C = x, D = k
- 두 번째 행: C = y, D = k
- 따라서 서브쿼리의 결과는 C의 값으로 ['x', 'y']가 된다.
- SELECT B FROM R1 WHERE C (서브쿼리);
- 메인 쿼리는 R1 테이블에서 C가 서브쿼리의 결과인 x 또는 y인 경우에 해당하는 B 값을 선택한다.
- C가 x인 행을 찾으면:
- 첫 번째 행: C = x → B = a
- 두 번째 행: C = x → B = b
- C가 y인 행은 없다.
- 따라서 C가 x인 행만 찾을 수 있으며, 그 결과는 B = a와 B = b이다.
- 최종적으로 B 열에서 a와 b를 결과로 출력하게 된다.
14. 아래는 애플리케이션 테스트 관리에 대한 내용이다. 설명하는 답을 보기에서 골라 작성하시오.
| - 모든 분기와 조건의 조합을 고려하나 모든 조합을 테스트하는 대신에 테스트가 필요한 중요한 조합을 찾아내는데에 중점을 둔다. - 특정 조건을 수행할 때 다른 조건과는 상관없이 전체 결과에 영향을 미치는 조건만을 테스트한다. - 각각의 파라미터는 적어도 한 번은 최종 결과에 영향을 주어야 한다. |
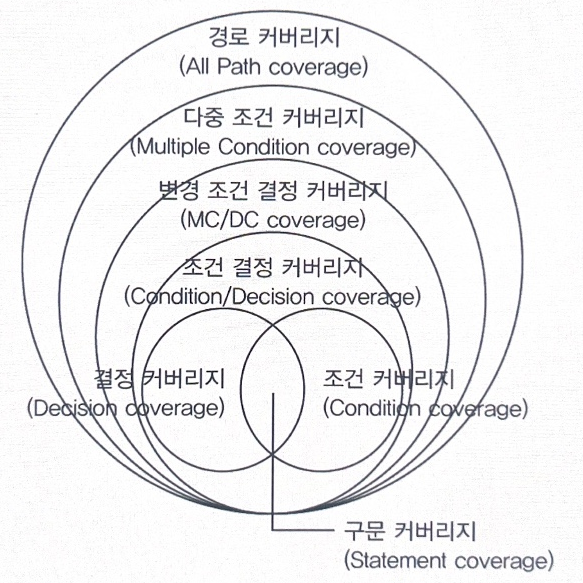
| ㄱ. 구문 커버리지 ㄴ. 결정 커버리지 ㄷ. 조건 커버리지 ㄹ. 변경 조건/결정 커버리지 ㅁ. 다중 조건 커버리지 ㅂ. 경로 커버리지 ㅅ. 조건/결정 커버리지 |
ㄹ. 변경 조건/결정 커버리지
* 코드 커버리지(Code Coverage)
- 프로그램의 소스코드의 테스트 수행 정도를 표시한다.
| 구문 커버리지 (Statement Coverage) |
- 코드 구조 내의 모든 구문에 대해 한 번 이상 수행하는 테스트 커버리지 - 예를 들어 반복문에서 10회 반복 테스트를 수행해야 100% 테스트가 완료된다고 가정할 때 5회만 반복한 경우 구문 커버리지는 50%이다. |
| 조건 커버리지 (Condition Coverage) |
결정 포인트 내의 모든 개별 조건식에 대해 수행하는 테스트 커버리지 |
| 결정 커버리지 (Decision Coverage) |
- 결정포인트 내의 모든 분기문에 대해 수행하는 테스트 커버리지 - 예를 들어 10개의 분기문 중에서 4개의 분기만 테스트가 완료되었다고 가정하면 결정 커버리지는 40%이다. - 분기 커버리지(Branch Coverage)라고도 한다. |
| 조건/결정 커버리지 (Condition/Decision Coverage) |
- 결정 포인트 T/F, 개별 조건식 T/F - 즉, 코드 내의 결정 포인트에서 발생하는 모든 조건식의 결과(true/false)와 전체 결정식의 결과(true/false)를 모두 고려하여 측정 |
| 변경 조건/결정 커버리지 (Modified Condition/ Decision Coverage) |
- 조건과 결정을 복합적으로 고려한 측정 방법 - 결정 포인트 내의 다른 개별적인 조건식 결과에 상관없이 전체 조건식의 결과에 영향을 주는 테스트 커버리지 - 모든 결정포인트 내의 개별 조건식은 적어도 한 번 T/F |
| 다중 조건 커버리지 (Multiple Condition Coverage) |
- 모든 개별 조건식의 true, false 조합 중 테스트에 의해 실행된 조합을 측정 - 100% 달성하기 위해서는 모든 개별 조건식 조합을 실행해야 하므로 다른 커버리지에 비해 상대적으로 많은 테스트 케이스가 필요하다. |
| 경로 커버리지 (Path Coverage) |
- 모든 가능한 실행 경로를 고려하여 테스트를 수행하는 테스트 커버리지 - 각 조건문, 반복문 및 분기점에서의 모든 조합을 포함한 경로를 검사하여 코드의 논리적 오류를 찾아내는 데 중점을 둔다. |
15. 다음 아래 내용을 보고 보기에서 알맞은 용어를 골라 작성하시오.
| - 인터넷 공격자의 존재를 숨기면서 이 공격자에게 시스템에 대한 무제한 접근 권한을 부여하는 악성 프로그램이다. - 해커가 자신의 존재를 숨기면서 허가되지 않은 컴퓨터나 소프트웨어에 접근할 수 있도록 설계된 도구이다. - 일반적으로 펌웨어, 가상화 계층 등의 다양한 시스템 영역에서 작동하며, 운영체제의 시스템콜을 해킹하여 악성코드의 실행여부를 숨겨 안티바이러스 탐지를 우회할 수 있다. |
| ㄱ. Worm ㄴ. Trojan Horse ㄷ. Backdoor ㄹ. Virus ㅁ. Ransomware ㅂ. Spyware ㅅ. Rootkit |
ㅅ. Rootkit
| 웜 (Worm) |
스스로를 복제하는 악성 소프트웨어 컴퓨터 프로그램으로, 바이러스가 다른 실행 프로그램에 기생하여 실행되는 데 반해 웜은 독자적으로 실행되며 다른 실행 프로그램이 필요하지 않다. |
| 트로이 목마 (Trojan Horse) |
악성 루틴이 숨어 있는 프로그램으로, 겉보기에는 정상적인 프로그램으로 보이지만 실행하면 악성 코드를 실행한다. |
| 백도어 (Back Door) |
- 프로그램이나 손상된 시스템에 허가되지 않는 접근을 할 수 있도록 정상적인 보안 절차를 우회하는 악성 소프트웨어이다. - 백도어 공격 도구로는 NetBus, Back Orifice, RootKit 등이 있다. |
| 바이러스 (Virus) |
다른 독립적 프로그램의 코드 내에 스스로를 주입한 다음, 그 프로그램이 악성 행동을 하고 스스로 확산되도록 강제하는 컴퓨터 코드이다. |
| 랜섬웨어 (Ransomware) |
컴퓨터 시스템을 감염시켜 접근을 제한하고 일종의 몸값을 요구하는 악성 소프트웨어의 한 종류이다. |
| 스파이웨어 (Spyware) |
- 사용자 동의 없이 컴퓨터나 모바일 장치에 설치되어 사용자 정보를 수집하는 악성 소프트웨어이다. - 사용자의 인터넷 활동, 검색 기록, 로그인 정보, 개인 파일 등의 민감한 데이터를 수집하여 제3자에게 전송한다. - 주로 광고 목적이나 사기 행위를 위해 사용되며, 사용자의 프라이버시와 보안을 위협한다. |
| 루트킷 (RootKit) |
- 공격자가 시스템에 접근하여 자신의 존재를 숨기고 시스템 제어 권한을 장악하도록 설계된 악성 소프트웨어이다. - 일반적으로 운영체제의 핵심 계층, 펌웨어, 가상화 계층에 숨겨져 실행된다. - 운영체제의 시스템 호출을 해킹하여 악성코드의 실행 여부를 숨겨 안티바이러스 탐지를 우회할 수 있으며, 이를 통해 해커가 시스템을 은밀히 조작할 수 있도록 한다. |
16. 다음 Java 코드를 보고 알맞은 출력 값을 작성하시오.
class classOne {
int a, b;
public classOne(int a, int b) {
this.a = a;
this.b = b;
}
public void print() {
System.out.println(a + b);
}
}
class classTwo extends classOne {
int po = 3;
public classTwo(int i) {
super(i, i+1);
}
public void print() {
System.out.println(po*po);
}
}
public class main {
public static void main(String[] args) {
classOne one = new classTwo(10);
one.print();
}
}
9
* Java언어, 상속, 오버라이딩
- 이 문제는 Java의 상속과 메서드 오버라이딩 개념을 활용하여 출력 결과를 예상하는 문제이다.
- classOne one = new classTwo(10);를 통해 classTwo 객체가 생성되며, classOne 타입의 참조 변수 one에 할당된다. new classTwo(10)의 생성자는 super(10, 11)을 호출하므로 a는 10, b는 11로 초기화된다.
- 이후, one.print()가 호출된다. classOne 타입의 참조 변수를 사용하지만, 실제 객체는 classTwo 타입이므로 동적 바인딩에 의해 classTwo의 print() 메서드가 호출된다.
- classTwo의 print() 메서드는 po * po 값을 출력하므로, 3 * 3 = 9가 출력된다.
17. 다음 내용을 보고 보기에서 알맞은 용어를 골라 작성하시오.
| - 불특정 다수가 아닌 명확한 표적을 정하여 지속적인 정보수집 후 공격감행할 수 있다. - 시스템에 직접 침투하는 것 뿐 아니라 표적 내부직원들이 이용하는 다양한 단말을 대상으로 한다. - 한가지 기술만이 아닌 Zero-day 취약점, 악성코드 등 다양한 보안 위협 공격 기술을 사용한다. - 일반적으로 공격은 침투, 검색, 수집 및 유출의 4단계로 실행되며, 각 단계별로 다양한 공격 기술을 사용한다. |
| ㄱ. 사회공학 기법 ㄴ. Adware ㄷ. MITM ㄹ. XDR ㅁ. Replace attack ㅂ. Key logger attack ㅅ. APT |
ㅅ. APT
- 보안 용어, 지속적인 공격, 침투, 검색, 수집 및 유출의 4단계
| 사회공학 기법 | - 사람의 심리적 취약점을 이용하여 개인 정보나 보안 정보를 유출하게 만드는 기법 - 예시로는 피싱, 스미싱 등이 있다. |
| Adware | - 광고를 표시하거나, 사용자의 인터넷 사용 정보를 수집하는 프로그램 - 대부분 사용자의 동의 없이 설치되며 성가신 광고를 반복적으로 보여준다. |
| MITM (Man-In-The-Middle) |
통신하는 두 당사자 사이에 공격자가 위치하여 통신 내용을 가로채거나 조작하는 공격 방식 |
| XDR (Extended Detection and Response) |
여러 보안 위협 요소와 데이터를 통합하여 탐지하고 대응하는 시스템으로, 여러 보안 장치를 통합하여 전체적 위협에 대한 가시성을 제공하는 기술 |
| Replace Attack | 동일한 ID나 패스워드를 입력하여 데이터를 가로채는 방식으로, 공격자가 다른 사용자 정보를 대체하거나 조작하여 공격을 수행하는 기법 |
| 키 로거 (Key Logger) |
컴퓨터 사용자의 키보드 움직임을 탐지해 ID, 패스워드 등 개인의 중요한 정보를 몰래 빼가는 공격 방법 |
| APT (Advanced Persistent Threat, 지능적 지속 위협) |
- 특정 조직이나 단체를 대상으로 장기적이고 지속적인 공격을 수행하여 정보를 유출하거나 권한을 획득하려는 공격 방식 - 공격 단계는 침투, 검색, 수집 및 유출의 4단계로 이루어진다. |
18. 아래의 SQL 코드와 테이블을 참고하여 결과 값을 작성하시오.
<TABLE>
| EMPNO | SAL |
| 100 | 1000 |
| 200 | 3000 |
| 300 | 1500 |
SELECT COUNT(*) FROM TABLE
WHERE EMPNO > 100 AND SAL >= 3000 OR EMPNO = 200
1
- 이 SQL 문제는 TABLE 테이블에서 특정 조건을 만족하는 행의 개수를 계산하는 문제이다.
- EMPNO가 100보다 크고 SAL이 3000 이상인 행 또는 EMPNO가 200인 행을 찾는다.
- 따라서 EMPNO = 200인 두 번째 행이 유일하게 조건을 만족하므로 COUNT(*) 결과는 1이다.
19. 다음 C언어 코드의 알맞은 출력 값을 작성하시오.
#include<stdio.h>
#include<ctype.h>
int main(){
char*p = "It is 8";
char result[100];
int i;
for(i=0; p[i]!='\0'; i++){
if(isupper(p[i]))
result[i] = (p[i]-'A'+5)% 25 + 'A';
else if(islower(p[i]))
result[i] = (p[i]-'a'+10)% 26 + 'a';
else if(isdigit(p[i]))
result[i] = (p[i]-'0'+3)% 10 + '0';
else if(!(isupper(p[i]) || islower(p[i]) || isdigit(p[i])))
result[i] = p[i];
}
result[i] = '\0';
printf("%s\n",result);
return 0;
}
Nd sc 1
* C언어, 시저 암호 알고리즘
- 해당 프로그램은 문자열 "It is 8"에 있는 각 문자를 변환하여 새로운 문자열 result를 출력하는 코드이다.
- 변환은 문자 유형(대문자, 소문자, 숫자, 기타 문자)에 따라 다르게 이루어진다.
- 코드 분석 및 변환 과정
- 입력 문자열과 배열 초기화:
- char* p = "It is 8";로 입력 문자열이 설정된다.
- char result[100];는 변환된 문자열을 저장할 배열이다.
- i는 루프 인덱스로, 문자열을 문자 하나씩 순회하며 변환을 수행한다.
- for 루프와 문자별 변환 조건:
- for(i = 0; p[i] != '\0'; i++): 입력 문자열 p의 각 문자에 대해 변환을 수행 후, 종료 문자 '\0'을 만날 때까지 루프를 반복
- 각 문자는 조건에 따라 다음과 같이 변환:
- 대문자 (isupper(p[i])):
- 대문자인 경우 (p[i] - 'A' + 5) % 25 + 'A'를 통해 변환
- 이는 대문자를 알파벳 순서로 5글자 앞으로 이동시킨다.
- 소문자 (islower(p[i])):
- 소문자인 경우 (p[i] - 'a' + 10) % 26 + 'a'를 통해 변환
- 이는 소문자를 알파벳 순서로 10글자 앞으로 이동시킨다.
- 숫자 (isdigit(p[i])):
- 숫자인 경우 (p[i] - '0' + 3) % 10 + '0'로 변환
- 이는 숫자를 3 증가시킨다.
- 기타 문자:
- p[i]가 대문자, 소문자, 숫자가 아니면 변환하지 않고 그대로 result[i]에 저장
- 대문자 (isupper(p[i])):
- 변환 결과:
- "I": 대문자이므로 (I - 'A' + 5) % 25 + 'A' -> (8 + 5) % 25 + 'A' -> 'N'
- "t": 소문자이므로 (t - 'a' + 10) % 26 + 'a' -> (19 + 10) % 26 + 'a' -> 'd'
- " ": 공백은 그대로 유지 -> ' '
- "i": 소문자이므로 (i - 'a' + 10) % 26 + 'a' -> (8 + 10) % 26 + 'a' -> 's'
- "s": 소문자이므로 (s - 'a' + 10) % 26 + 'a' -> (18 + 10) % 26 + 'a' -> 'c'
- " ": 공백은 그대로 유지 -> ' '
- "8": 숫자이므로 (8 - '0' + 3) % 10 + '0' -> (8 + 3) % 10 + '0' -> '1'
- 출력값:
- 변환된 문자열 result는 "Nd sc 1"이 된다.
- 입력 문자열과 배열 초기화:
20. 다음 내용을 보고 알맞은 용어를 작성하시오.
| - 구체적인 클래스에 의존하지 않고 서로 연관되거나 의존적인 객체들의 조합을 만드는 인터페이스를 제공하는 패턴이다. - 연관성이 있는 객체 군이 여러 개 있을 경우 이들을 묶어 추상화하고, 어떤 구체적인 상황이 주어지면 팩토리 객체에서 집합으로 묶은 객체 군을 구현화하는 생성 패턴이다. - 관련성 있는 여러 종류의 객체를 일관된 방식으로 생성하는 경우에 유용하다. - Kit라고도 불린다. |
Abstract Factory
* 디자인 패턴(Design Pattern)
- 객체지향 프로그래밍 설계 시 유사한 상황에서 구조적인 문제를 해결할 수 있도록 방안을 제공
[생성 패턴]
- 객체를 생성하는 것과 관련된 패턴으로, 객체의 생성과 변경이 전체 시스템에 미치는 영향을 최소화하도록 만들어주어 유연성을 높일 수 있고 코드를 유지하기 쉬운 편이다.
- 객체의 생성과 참조 과정을 추상화함으로써 시스템을 개발할 때 부담을 덜어준다.
- 클래스나 객체의 생성과 참조과정을 정의하는 패턴
| Factory Method |
- 객체를 생성하기 위한 인터페이스를 정의하며 어떤 클래스가 인스턴스화될 것인지는 서브 클래스가 결정하도록 함 - 객체를 생성하는 인터페이스와 실제 객체를 생성하는 클래스 분리 가능 - Virtual -Constructor(가상 생성자) 패턴이라도고 함 |
| Singleton | - 전역 변수를 사용하지 않고 객체를 하나만 생성하도록 한다. - 생성된 객체를 어디에서든지 참조할 수 있도록 하는 패턴 |
| Prototype | - 원본 객체를 복제하여 객체를 생성하는 패턴 - 일반적인 방법으로 객체를 생성하고 비용이 많이 소요되는 경우에 주로 사용 |
| Builder | 작게 분리된 인스턴스를 조립하듯 조합하여 객체를 생성 |
| Abstract Factory |
- 구체적인 클래스에 의존하지 않고 서로 연관되거나 의존적인 객체들의 조합을 만드는 인터페이스를 제공하는 패턴 - 관련된 서브 클래스를 그룹지어 한 번에 교체할 수 있음 |
[구조 패턴]
- 클래스나 객체를 조합해 더 큰 구조를 만드는 패턴
- 복잡한 형태의 구조를 갖는 시스템을 개발하기 쉽게 만들어주는 패턴
- 새로운 기능을 가진 복합 객체를 효과적으로 작성할 수 있다.
- ex) 서로 다른 인터페이스를 지닌 2개의 객체를 묶어 단일 인터페이스를 제공하거나 객체들을 서로 묶어 새로운 기능을 제공하는 패턴. 프로그램 내의 자료구조나 인터페이스 구조 등을 설계하는데 많이 활용
| Composite | 여러 개로 객체로 구성된 복합 객체와 단일 객체를 클라이언트에서 구별없이 다루게 해주는 패턴 |
| Adapter | 호환성이 없는 인터페이스 때문에 함께 사용할 수 없는 (기존)클래스를 개조하여 함께 작동할 수 있도록 해주는 패턴 |
| Bridge | 기능 클래스 계층과 구현 클래스 계층을 연결하고, 구현부에서 추상 계층을 분리하여 각자 독립적으로 변형할 수 있도록 해주는 패턴 |
| Decorator | 객체의 결합을 통해 기능을 동적으로 유연하게 확장할 수 있게 해주는 해턴 |
| Facade | - '건물의 (앞쪽)정면' - Facade 인터페이스를 제공하여 facade 객체를 통해서만 모든 관계가 이루어질 수 있도록 인터페이스를 단순화 - 클래스 간 의존 관계가 줄어들고 복잡성이 낮아지는 효과 |
| Flyweight | 인스턴스가 필요할 때마다 매번 생성하는 것이 아니고 가능한 한 공유해서 사용함으로써 메모리를 절약하는 패턴 |
| Proxy | - '대리인'이라는 뜻으로, 뭔가를 대신해서 처리하는 것 - 접근이 어려운 객체와 여기에 연결하려는 객체 사이에서 인터페이스 역할을 수행하는 패턴 |
- 반복적으로 사용되는 객체들의 상호작용을 패턴화한 것으로, 클래스나 객체들이 상호작용하는 방법과 책임을 분산하는 방법을 정의한다.
- 메세지 교환과 관련된 것으로, 객체 간의 행위나 알고리즘 등과 관련된 패턴을 말한다.
| Chain of Responsibility (책임 연쇄) |
- 요청을 처리할 수 있는 객체가 둘 이상 존재하여 한 객체가 처리하지 못하면 다음 객체로 넘어가는 형태의 패턴 - 요청을 처리할 수 있는 각 객체들이 고리(chain)로 묶여 있어 요청이 해결될 때까지 고리를 따라 책임이 넘어감 |
| Iterator (반복자) |
- 자료 구조와 같이 접근이 잦은 객체에 대해 동일한 인터페이스를 사용하도록 하는 패턴 - 내부 표현 방법의 노출 없이 복합 객체의 원소를 순차적으로 접근할 수 있는 방법 제공 |
| Command (명령) |
- 요청을 객체의 형태로 캡슐화하여 재이용하거나 취소할 수 있도록 요청에 필요한 정보를 저장하거나 로그에 남기는 패턴 - 요청에 사용되는 각종 명령어들을 추상 클래스와 구체 클래스로 분리하여 단순화함 |
| Interpreter (해석자) |
- 언어의 문법 표현을 정의하는 패턴 - SQL 이나 통신 프로토콜과 같은 것을 개발할 때 문법 규칙을 클래스화한 구조 |
| Memento (기록) |
- 특정 시점에서의 객체 내부 상태를 객체화함으로써 이후 요청에 따라 객체를 해당 시점의 상태로 돌릴 수 있는 기능을 제공하는 패턴 - Ctrl+Z와 같은 되돌리기 기능을 개발할 때 주로 이용 |
| Observer (감시자) |
- 한 객체의 상태가 변하면 객체에 상속되어 있는 다른 객체들에게 변화된 상태를 전달하는 패턴 - 객체 사이에 일대다의 존속성을 정의 |
| State (상태) |
- 객체의 내부 상태에 따라 동일한 동작을 다르게 처리해야 할 때 사용하는 패턴, 행위를 변경할 수 있게 함 - 이렇게 하면 객체는 마치 클래스를 바꾸는 것처럼 보인다. |
| Strategy (전략) |
- 동일한 계열의 알고리즘들을 개별적으로 캡슐화하여 상호 교환할 수 있게 정의하는 패턴 - 클라이언트는 독립적으로 원하는 알고리즘을 선택하여 사용할 수 있으며, 클라이언트에 영향 없이 알고리즘의 변경이 가능함 - 즉, 클라이언트에게 알고리즘이 사용하는 데이터나 그 구조를 숨겨주는 역할을 한다. |
| Visitor (방문자) |
- 각 클래스들의 데이터 구조에서 처리 기능을 분리하여 별도의 클래스로 구성하는 패턴 - 즉, 객체 구조의 요소들에 수행할 오퍼레이션을 표현한 패턴 - 분리된 처리 기능은 각 클래스를 방문(visit)하여 수행함 - 오퍼레이션이 처리할 요소의 클래스를 변경하지 않고도 새로운 오퍼레이션을 정의할 수 있게 함 |
| Template Method |
- 상위 클래스에서 골격을 정의하고, 하위 클래스에서 세부 처리를 구체화하는 구조의 패턴 - 유사한 서브 클래스를 묶어 공통된 내용을 상위 클래스에서 정의함으로써 코드의 양 축소, 유지보수 용이 |
| Mediator (중재자) |
- 수많은 객체들 간의 복잡한 상호작용(interface)을 캡슐화 하여 객체로 정의하는 패턴 - 객체 간의 통제와 지시의 역할을 하는 중재자를 두어 객체지향의 목표를 달성하게 해줌 - 객체 사이의 의존성을 줄여 결합도를 감소시킬 수 있음 |
2024.09.23 - [기술 노트] - [Study] 디자인 패턴(Design Pattern)
[Study] 디자인 패턴(Design Pattern)
1. 디자인 패턴자주 사용하는 설계 형태를 정형화해서 이를 유형별로 설계 템플릿을 만들어둔 것으로, 소프트웨어 개발 중 나타나는 과제를 해결하기 위한 방법 중 한가지이다.다시 말헤, 모듈
juble00.tistory.com

'정보처리기사' 카테고리의 다른 글
| [정보처리기사 요약정리] PART 1. 소프트웨어 설계 + 기출포함 (12) | 2024.10.18 |
|---|---|
| [정보처리기사 실기 기출] 2024년 2회 (14) | 2024.10.17 |
| [정보처리기사 실기 기출] 2023년 3회 (16) | 2024.10.16 |
| [정보처리기사 실기 기출] 2023년 2회 (4) | 2024.10.16 |
| [정보처리기사 실기 기출] 2023년 1회 (6) | 2024.10.15 |