Problem
Huffman coding assigns variable length codewords to fixed length input characters based on their frequencies. More frequent characters are assigned shorter codewords and less frequent characters are assigned longer codewords. All edges along the path to a character contain a code digit. If they are on the left side of the tree, they will be a 0 (zero). If on the right, they'll be a 1 (one). Only the leaves will contain a letter and its frequency count. All other nodes will contain a null instead of a character, and the count of the frequency of all of it and its descendant characters.
For instance, consider the string ABRACADABRA. There are a total of 11 characters in the string. This number should match the count in the ultimately determined root of the tree. Our frequencies are A=5, B=2, R=2, C=1 and D=1. The two smallest frequencies are for C and D, both equal to 1, so we'll create a tree with them. The root node will contain the sum of the counts of its descendants, in this case 1 + 1 = 2. The left node will be the first character encountered, C, and the right will contain D. Next we have 3 items with a character count of 2: the tree we just created, the character B and the character R. The tree came first, so it will go on the left of our new root node. B will go on the right. Repeat until the tree is complete, then fill in the 1's and 0's for the edges. The finished graph looks like:
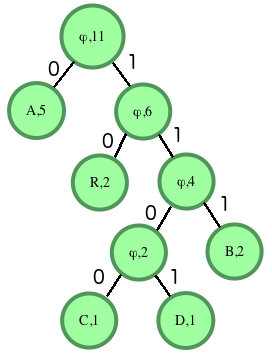
Input characters are only present in the leaves. Internal nodes have a character value of ϕ (NULL). We can determine that our values for characters are:
A - 0
B - 111
C - 1100
D - 1101
R - 10Our Huffman encoded string is:
A B R A C A D A B R A
0 111 10 0 1100 0 1101 0 111 10 0
or
01111001100011010111100To avoid ambiguity, Huffman encoding is a prefix free encoding technique. No codeword appears as a prefix of any other codeword.
To decode the encoded string, follow the zeros and ones to a leaf and return the character there.
You are given pointer to the root of the Huffman tree and a binary coded string to decode. You need to print the decoded string.
Function Description
Complete the function decode_huff in the editor below. It must return the decoded string.
decode_huff has the following parameters:
- root: a reference to the root node of the Huffman tree
- s: a Huffman encoded string
Input Format
There is one line of input containing the plain string, s. Background code creates the Huffman tree then passes the head node and the encoded string to the function.
Constraints
1 ≤ |s| ≤ 25
Output Format
Output the decoded string on a single line.
Sample Input
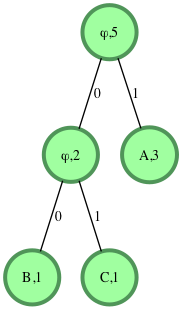
s="1001011"Sample Output
ABACAExplanation
S="1001011"
Processing the string from left to right.
S[0]='1' : we move to the right child of the root. We encounter a leaf node with value 'A'. We add 'A' to the decoded string.
We move back to the root.
S[1]='0' : we move to the left child.
S[2]='0' : we move to the left child. We encounter a leaf node with value 'B'. We add 'B' to the decoded string.
We move back to the root.
S[3] = '1' : we move to the right child of the root. We encounter a leaf node with value 'A'. We add 'A' to the decoded string.
We move back to the root.
S[4]='0' : we move to the left child.
S[5]='1' : we move to the right child. We encounter a leaf node with value C'. We add 'C' to the decoded string.
We move back to the root.
S[6] = '1' : we move to the right child of the root. We encounter a leaf node with value 'A'. We add 'A' to the decoded string.
We move back to the root.
Decoded String = "ABACA"
허프만 코딩은 입력된 고정 길이의 문자를 빈도에 따라 가변 길이 코드로 변환하는 방법입니다. 더 자주 등장하는 문자는 더 짧은 코드로, 덜 자주 등장하는 문자는 더 긴 코드로 변환됩니다. 경로의 모든 간선에는 코드 숫자가 할당되며, 왼쪽으로 갈 경우 0, 오른쪽으로 갈 경우 1이 할당됩니다. 리프(leaf) 노드에만 문자와 빈도 값이 포함되고, 다른 노드는 문자 대신 null을 포함하며 해당 노드와 자식 노드들의 빈도 합이 저장됩니다.
예를 들어, 문자열 "ABRACADABRA"가 주어졌을 때, 총 11개의 문자가 있고, 빈도는 다음과 같습니다:
- A=5, B=2, R=2, C=1, D=1
허프만 트리를 구성하여 문자마다 고유한 코드값을 할당한 후, 문자열을 인코딩하면 다음과 같은 코드가 나옵니다:
A - 0
B - 111
C - 1100
D - 1101
R - 10인코딩된 문자열은 다음과 같습니다:
A B R A C A D A B R A
0 111 10 0 1100 0 1101 0 111 10 0
or
01111001100011010111100허프만 디코딩은 이진 트리의 루트부터 시작하여 0 또는 1 값을 따라가면서 리프 노드에 도달할 때까지 이동한 뒤, 해당 리프 노드의 문자를 복원하여 원래 문자열을 반환합니다.
함수 설명
decode 함수는 허프만 트리의 루트 노드와 인코딩된 문자열을 받아 디코딩된 문자열을 반환해야 합니다.
입력 형식
- 하나의 인코딩된 문자열 s가 주어집니다.
- 배경 코드가 허프만 트리를 생성하고, 루트 노드와 인코딩된 문자열을 함수에 전달합니다.
제약 사항
- 1 ≤ |s| ≤ 25
출력 형식
- 디코딩된 문자열을 한 줄로 출력합니다.
Solution
/*
class Node
public int frequency; // the frequency of this tree
public char data;
public Node left, right;
*/
void decode(String s, Node root) {
Node current = root;
StringBuilder decodedString = new StringBuilder();
for (char bit : s.toCharArray()) {
// 왼쪽(0) 또는 오른쪽(1)으로 이동
if (bit == '0') {
current = current.left;
} else {
current = current.right;
}
// 리프 노드에 도달하면 문자를 추가하고 루트로 돌아감
if (current.left == null && current.right == null) {
decodedString.append(current.data);
current = root;
}
}
System.out.println(decodedString.toString());
}
- 초기화:
- Node current는 현재 탐색 중인 위치를 나타내며, 초기값은 트리의 루트입니다.
- StringBuilder decodedString은 디코딩된 결과 문자열을 저장할 객체입니다.
- 문자열 순회:
- s.toCharArray()를 통해 인코딩된 문자열의 각 비트를 하나씩 순회합니다.
- 각 비트(0 또는 1)를 확인하여 트리의 왼쪽 또는 오른쪽 자식 노드로 이동합니다.
- 0인 경우 왼쪽 자식(current.left)으로 이동
- 1인 경우 오른쪽 자식(current.right)으로 이동
- 리프 노드 확인:
- current 노드가 리프 노드(자식 노드가 없는 노드)일 경우, 해당 노드의 data를 decodedString에 추가합니다.
- 문자 추가 후에는 다시 루트 노드로 돌아가서 새로운 문자 디코딩을 시작합니다.
- 출력:
- 모든 비트를 순회한 후 decodedString을 출력하여 디코딩된 결과를 보여줍니다.
1. StringBuilder의 용도, 사용 목적, 사용 이유
- StringBuilder란?
- StringBuilder는 Java에서 문자열을 동적으로 처리하기 위해 제공되는 클래스입니다. 일반적인 String은 불변(immutable) 객체로, 수정할 수 없기 때문에 문자열을 연결하거나 수정할 때 새로운 String 객체가 생성됩니다.
- 반면, StringBuilder는 가변(mutable) 객체로, 내부 버퍼를 사용하여 문자열을 수정할 때 새로운 객체를 생성하지 않고 기존 객체에서 수정하므로 메모리와 속도 측면에서 효율적입니다.
- StringBuilder 사용 이유
- 이 코드에서는 디코딩된 결과 문자열을 하나의 문자열로 연결하기 위해 StringBuilder를 사용합니다.
- 인코딩된 문자열을 한 문자씩 디코딩하여 StringBuilder에 저장하면, 전체 디코딩이 완료된 후 toString() 메서드를 호출하여 최종 문자열을 한 번에 출력할 수 있습니다.
- StringBuilder는 디코딩 과정에서 문자열을 반복적으로 연결하는데 효율적이므로, String보다 속도가 빠르고 메모리를 절약하는 이점이 있습니다.
2. if (bit == '0') { current = current.left; } else { current = current.right; } 조건의 이유
- 왜 0일 때 왼쪽, 1일 때 오른쪽으로 이동하는가?
- 허프만 트리에서는 왼쪽 경로가 0, 오른쪽 경로가 1로 정의됩니다. 허프만 코딩은 빈도에 따라 트리를 생성하기 때문에, 0과 1을 이용해 트리의 특정 위치로 이동하면서 각 문자의 코드 패턴을 찾을 수 있습니다.
- 예를 들어, 문자열의 첫 번째 비트가 1이라면 트리의 오른쪽으로 이동하여 해당 위치의 노드를 탐색하게 되고, 0이라면 왼쪽으로 이동하여 왼쪽 자식 노드를 탐색하게 됩니다.
- 이런 방식으로 이진 트리를 따라가면서 0과 1을 해석해 나가면, 리프 노드에 도달할 때마다 해당 문자에 대한 디코딩을 완료할 수 있습니다.
3. 두 번째 if 문에서 current = root;를 다시 하는 이유
- current = root;의 역할
- 두 번째 if 조건에서 current.left == null && current.right == null은 현재 노드가 리프 노드(문자를 포함한 최종 노드)임을 확인하는 조건입니다. 리프 노드에 도달하면, 해당 노드의 문자를 디코딩된 결과 문자열에 추가해야 합니다.
- decodedString.append(current.data);를 통해 현재 노드의 데이터를 추가한 후, 다음 문자를 디코딩하기 위해 다시 트리의 루트 노드로 이동해야 합니다.
- 허프만 트리는 인코딩된 문자열을 따라 하나씩 이동하다가 리프 노드에 도달할 때마다 루트로 돌아가서 새로운 경로를 탐색해야 하기 때문에, current = root;를 통해 새로운 문자 디코딩을 시작할 준비를 하는 것입니다.

'코딩 테스트' 카테고리의 다른 글
| [백준] 3052번 자바, BufferedWriter (0) | 2024.11.22 |
|---|---|
| [HackerRank] No Prefix Set (4) | 2024.11.12 |
| [HackerRank] Tree: Preorder Traversal (8) | 2024.11.11 |
| [HackerRank] Breadth First Search: Shortest Reach (2) | 2024.11.10 |
| [HackerRank] Jesse and Cookies (0) | 2024.11.10 |